基于OCR进行Bert独立语义纠错实践
摘要:本案例我们利用视频字幕识别中的文字检测与识别模型,增加预训练Bert进行纠错
本文分享自华为云社区《Bert特调OCR》,作者:杜甫盖房子。
做这个项目的初衷是发现图比较糊/检测框比较长的时候,OCR会有一些错误识别,所以想对识别结果进行纠错。一个很自然的想法是利用语义信息进行纠错,其实在OCR训练时加入语义信息也有不少工作,感兴趣的朋友可以了解一下,为了更大程度复用已有的项目,我们决定保留现有OCR单元,在之后加入独立语义纠错模块进行纠错。
本案例我们利用视频字幕识别中的文字检测与识别模型,增加预训练Bert进行纠错,最终效果如下:

我们使用ModelBox Windows SDK进行开发,如果还没有安装SDK,可以参考ModelBox端云协同AI开发套件(Windows)设备注册篇、ModelBox端云协同AI开发套件(Windows)SDK安装篇完成设备注册与SDK安装。
技能开发
这个应用对应的ModelBox版本已经做成模板放在华为云OBS中,可以用sdk中的solution.bat工具下载,接下来我们给出该应用在ModelBox中的完整开发过程:
1)下载模板
执行.\solution.bat -l可看到当前公开的技能模板:
███@DESKTOP-UUVFMTP MINGW64 /d/DEMO/modelbox-win10-x64-1.5.1 $ ./solution.bat -l start download desc.json 3942.12KB/S, percent=100.00% Solutions name: mask_det_yolo3 ... doc_ocr_db_crnn_bert
结果中的doc_ocr_db_crnn_bert即为文档识别应用模板,下载模板:
███@DESKTOP-UUVFMTP MINGW64 /d/DEMO/modelbox-win10-x64-1.5.1 $ ./solution.bat -s doc_ocr_db_crnn_bert ...
solution.bat工具的参数中,-l 代表list,即列出当前已有的模板名称;-s 代表solution-name,即下载对应名称的模板。下载下来的模板资源,将存放在ModelBox核心库的solution目录下。
2)创建工程
在ModelBox sdk目录下使用create.bat创建doc_ocr工程
███@DESKTOP-UUVFMTP MINGW64 /d/DEMO/modelbox-win10-x64-1.5.1 $ ./create.bat -t server -n doc_ocr -s doc_ocr_db_crnn_bert sdk version is modelbox-win10-x64-1.5.1 success: create doc_ocr in D:\DEMO\modelbox-win10-x64-1.5.1\workspace
create.bat工具的参数中,-t 表示创建事务的类别,包括工程(server)、Python功能单元(Python)、推理功能单元(infer)等;-n 代表name,即创建事务的名称;-s 代表solution-name,表示将使用后面参数值代表的模板创建工程,而不是创建空的工程。
workspace目录下将创建出doc_ocr工程,工程内容如下所示:
doc_ocr |--bin │ |--main.bat:应用执行入口 │ |--mock_task.toml:应用在本地执行时的输入输出配置,此应用为http服务 |--CMake:存放一些自定义CMake函数 |--data:存放应用运行所需要的图片、视频、文本、配置等数据 │ |--char_meta.txt:字形拆解文件,用来计算字形相似度 │ |--character_keys.txt:OCR算法的字符集合 │ |--GB2312.ttf:中文字体文件 │ |--test_http.py:应用测试脚本 │ |--text.jpg:应用测试图片 │ |--vocab.txt:tokenizer配置文件 |--dependence │ |--modelbox_requirements.txt:应用运行依赖的外部库在此文件定义,本应用依赖pyclipper、Shapely、pillow等工具包 |--etc │ |--flowunit:应用所需的功能单元存放在此目录 │ │ |--cpp:存放C++功能单元编译后的动态链接库,此应用没有C++功能单元 │ │ |--bert_preprocess:bert预处理功能单元,条件功能单元,判断是否需要纠错 │ │ |--collapse_position:归拢单句纠错结果 │ │ |--collapse_sentence:归拢全文纠错结果 │ │ |--det_post:文字检测后处理功能单元 │ │ |--draw_ocr:ocr结果绘制功能单元 │ │ |--expand_img:展开功能单元,展开文字检测结果 │ │ |--expand_position:展开功能单元,展开bert预处理结果 │ │ |--match_position:匹配纠错结果 │ │ |--ocr_post:ocr后处理功能单元 |--flowunit_cpp:存放C++功能单元的源代码,此应用没有C++功能单元 |--graph:存放流程图 │ |--doc_ocr.toml:默认流程图,http服务 │ |--modelbox.conf:modelbox相关配置 |--hilens_data_dir:存放应用输出的结果文件、日志、性能统计信息 |--model:推理功能单元目录 │ |--bert:Bert推理功能能单元 │ │ |--bert.toml:语义推理配置文件 │ │ |--bert.onnx:语义推理模型 │ |--det:文字检测推理功能单元 │ │ |--det.toml:文字检测推理功能单元的配置文件 │ │ |--det.onnx:文字检测onnx模型 │ |--ocr:文字识别推理功能单元 │ │ |--ocr.toml:文字识别推理功能单元的配置文件 │ │ |--ocr.onnx:文字识别onnx模型 |--build_project.sh:应用构建脚本 |--CMakeLists.txt |--rpm:打包rpm时生成的目录,将存放rpm包所需数据 |--rpm_copyothers.sh:rpm打包时的辅助脚本
3)查看流程图
doc_ocr工程graph目录下存放流程图,默认的流程图doc_ocr.toml与工程同名,将流程图可视化:
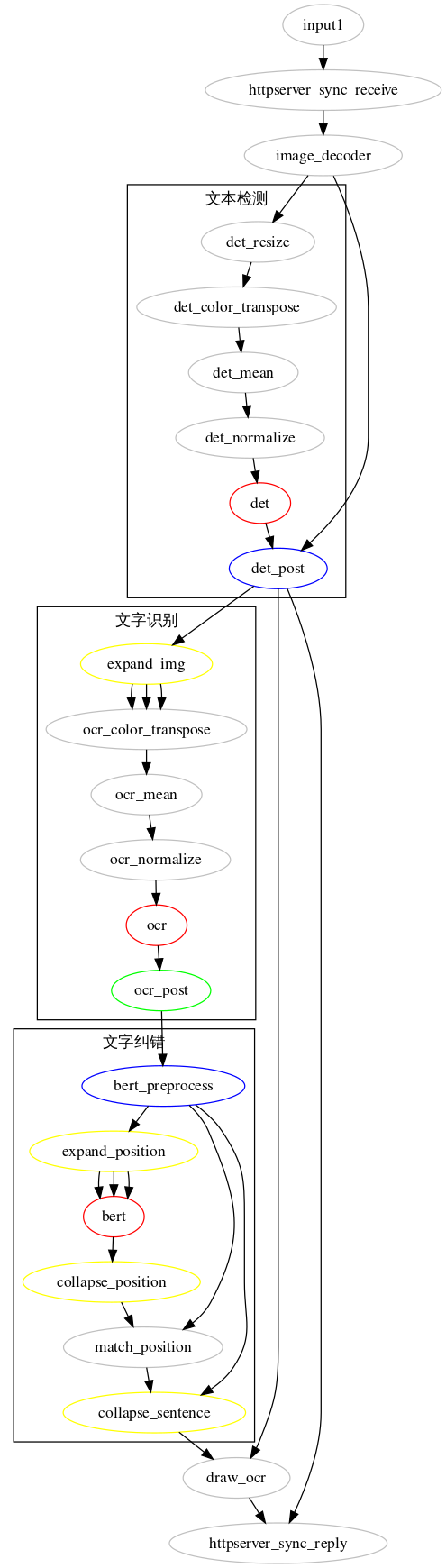
图示中,灰色部分为预置功能单元,其余颜色为我们实现的功能单元,其中绿色为一般通用功能单元,红色为推理功能单元,蓝色为条件功能单元,黄色为展开归拢功能单元。HTTP接收图解码后做预处理,接着是文字检测,模型后处理得到检测框,经过条件功能判断,检测到文字的图送入展开功能单元,切图进行文字识别,文字识别结果送入bert预处理单元判断是否需要进行纠错,如需纠错则再展开并行进行语义推理,不需要纠错的就直接进行结果绘制并返回。而未检测到文字的帧则直接返回。
4)核心逻辑
本应用核心逻辑中的文字检测与识别可以参考【ModelBox OCR实战营】视频字幕识别中的相关介绍,本文重点介绍文字纠错部分。
首先查看纠错预处理功能单元bert_preprocess:
def process(self, data_context): in_feat = data_context.input("in_feat") out_feat = data_context.output("out_feat") out_bert = data_context.output("out_bert") for buffer_feat in in_feat: ocr_data = json.loads(buffer_feat.as_object())['ocr_result'] score_data = json.loads(json.loads(buffer_feat.as_object())['result_score']) text_to_process = [] text_to_pass = [] err_positions = [] for i, (sent, p) in enumerate(zip(ocr_data, score_data)): if not do_correct_filter(sent, self.max_seq_length): text_to_pass.append((i, sent)) else: err_pos = find_err_pos_by_prob(p, self.prob_threshold) if not err_pos: text_to_pass.append((i, sent)) else: text_to_process.append(sent) err_positions.append(err_pos) if not text_to_process: out_feat.push_back(buffer_feat) else: out_dict = [] texts_numfree = [self.number.sub(lambda m: self.rep[re.escape(m.group(0))], s) for s in text_to_process] err_positions = check_error_positions(texts_numfree, err_positions) if err_positions is None: err_positions = [range(len(d)) for d in texts_numfree] batch_data = BatchData(texts_numfree, err_positions, self.tokenizer, self.max_seq_length) input_ids, input_mask, segment_ids, masked_lm_positions = batch_data.data ... return modelbox.Status.StatusCode.STATUS_SUCCESS
预处理单元对通过do_correct_filter函数对OCR结果进行判断,只对大于3个字的中文字符进行纠错:
def do_correct_filter(text, max_seq_length): if re.search(re.compile(r'[a-zA-ZA-Za-z]'), text): return False if len(re.findall(re.compile(r'[\u4E00-\u9FA5]'), text)) < 3: return False if len(text) > max_seq_length - 2: return False return True
通过find_err_pos_by_prob函数定位需要纠错的字符,只对OCR置信度小于阈值的字符进行纠错:
def find_err_pos_by_prob(prob, prob_threshold): if not prob: return [] err_pos = [i for i, p in enumerate(prob) if p < prob_threshold] return err_pos
如有需要纠错的字符,则将该句编码,进行语义推理。
语义推理后,通过collapse_position对推理结果进行解码,在match_position功能单元中使用shape_similarity函数计算语义推理结果与OCR结果的字符相似度:
def shape_similarity(self, char1, char2): decomp1 = self.decompose_text(char1) decomp2 = self.decompose_text(char2) similarity = 0.0 ed = edit_distance(safe_encode_string(decomp1), safe_encode_string(decomp2)) normalized_ed = ed / max(len(decomp1), len(decomp2), 1) similarity = max(similarity, 1 - normalized_ed) return similarity
其中,decompose_text函数将单个汉字编码为笔划级别的IDS,如:
华: ⿱⿰⿰丿丨⿻乚丿⿻一丨
华 +----+ | ⿱ | +----+ 化 十 +----+ +----+ | ⿰ | | ⿻ | +----+ +----+ 亻 七 一 丨 +----+ +----+ | ⿰ | | ⿻ | +----+ +----+ 丿 丨 乚 丿
计算语义推理结果字符与原OCR结果字符相似度之后,综合语义推理置信度与相似度判断是否接收纠错结果:
def accept_correct(self, confidence, similarity): if confidence + similarity >= self.all_conf \ and confidence >= self.confidence_conf \ and similarity >= self.similarity_conf: return True return False
5)三方依赖库
本应用依赖pyclipper、Shapely、pillow等工具包,ModelBox应用不需要手动安装三方依赖库,只需要配置在dependence\modelbox_requirements.txt,应用在编译时会自动安装。
技能运行
在项目目录下执行.\bin\main.bat运行应用,为了方便观察纠错结果,我们将日志切换为info:
███@DESKTOP-UUVFMTP MINGW64 /d/DEMO/modelbox-win10-x64-1.5.1/workspace/doc_ocr $ ./bin/main.bat default info ... [2022-12-27 15:20:40,043][ INFO][httpserver_sync_receive.cc:188 ] Start server at http://0.0.0.0:8083/v1/ocr_bert
另起终端,进入项目data目录下,运行test_http.py脚本进行测试:
███@DESKTOP-UUVFMTP MINGW64 /d/DEMO/modelbox-win10-x64-1.5.1/workspace/doc_ocr/data $ python test_http.py
可以在技能运行日志中观察到接受的纠错结果:
[2022-12-27 15:22:40,700][ INFO][match_position\match_position.py:51 ] confidence: 0.99831665, similarity: 0.6470588235294117, 柜 -> 相
同时,在data目录下可以看到应用返回的结果图片:

热门相关:地球第一剑 照见星星的她 薄先生,情不由己 第一神算:纨绔大小姐 寂静王冠