针对make工具和Makefile文件的学习心得
为什么要学习使用make工具?
在实际项目开发过程中,我们都会选择对项目进行模块化编程,即把可以重复使用的函数接口、数据结构等封装为源文件和头文件,这样可以大大提升项目程序的可移植、可读性和可维护性。但是当项目的源码数量较大时,就会导致封装的源文件和头文件的数量较多,此时就大大提高了项目的编译难度。为了提高项目的开发效率,我们必须学习使用make工具。
什么是make工具?
Make工具最早由斯图尔特·费尔德曼(Stuart Feldman)在1977年开发,作为UNIX系统的一部分推出。费尔德曼的Make工具解决了当时构建大型软件项目的复杂性问题,通过自动化依赖管理和构建过程,显著提高了开发效率。
为了获得更高的项目开发效率,所以GNU组织就在Linux系统中集成了Make工具,而Makefile就属于Make工具的一部分。Makefile是一个强大而灵活的工具,广泛应用于各种编程语言和项目中。通过定义目标、依赖和命令,Makefile可以自动化管理项目的构建过程,处理复杂的依赖关系,简化开发和部署工作。无论是编译大型C/C++项目,还是自动化生成文档和部署应用,Makefile都能提供极大的便利和效率提升。

Makefile可以理解为是一个脚本文件,用于管理项目的自动化构建过程,尤其在编译和链接复杂的源代码项目中非常有用。 Makefile文件的主要目的是简化和自动化项目的构建过程,包括编译源代码、链接生成可执行文件、清理中间文件等任务。
make工具的学习过程
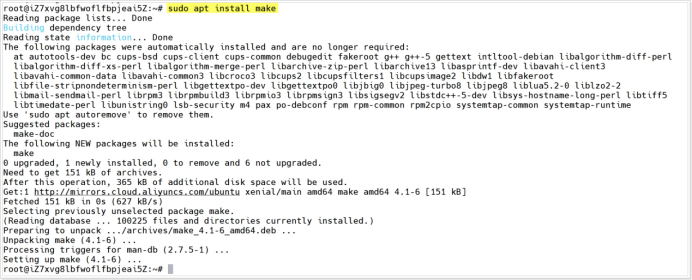
1. 安装make:sudo apt install make;并学习使用make
安装make流程
虽然linux系统是支持使用make的,但是make工具在linux系统中是默认未安装,所以我们需要确认linux系统联网的情况下,通过指令:sudo apt install make 完成安装。
学习使用make指令
安装完成之后,可以选择阅读man手册来了解make指令的使用规则和注意事项,如下所示:

经过阅读man手册,我们可知:
在Linux系统中,可以通过make指令完成Makefile文件的执行,make指令是一个命令工具,是一个解释Makefile文本的命令工具,也可以说它是一个工程管理器软件工具。
总而言之,Makefile是一个类似配置文件的文本(必须命名为Makefile或者makefile),用于描述如何去编译项目中的源文件以及完成一些其他操作,而make是解释该配置文件的命令工具。
make指令的相关特点
make只会对修改过的或者可执行目标文件不存在的.c文件进行编译
思考:如何判断“修改过”?
答:通过文件修改时间来判断,即可执行文件的修改时间早于.c文件,则代表.c文件进行了修改,make便会对其重新编译生成可执行文件。具体举例说明如下:
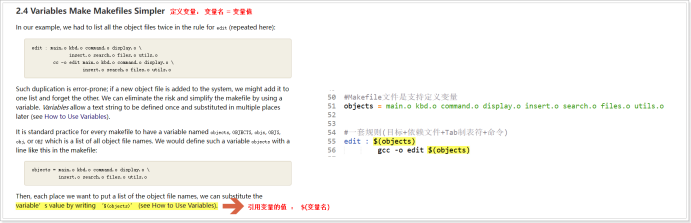
假设一个工程有四个源文件,分别为a.c、b.c、x.c和y.c,他们最终将会链接生成可执行文件image,如下图:

在开发的过程当中,如果修改了x.c源文件,就须重新生成x.o,再重新编译链接生成image文件,但是在由成千上万个源文件组成的庞大工程,比如Linux源码,一旦对若干个源文件进行了修改,则需要花费时间挑选出需重新编译的文件,否则就需要整体工程编译必将会浪费大量的时间;而这个挑选文件的任务可以交给make工程管理器,让make按照Makefile配置文件进行挑选所需文件进行编译处理。
使用make时,若不加 -f 选项,make会依次寻找,GNUmakefile、makefile、Makefile这三个文件
make是一个shell命令,用于执行Makefile文件中的命令(gcc xxx.c -o xxx),前提是执行make指令的时候,当前路径下需要有Makefile文件,如果没有Makefile文件,则指令make指令时会报错。如下图所示:

2. 学习编写Makefile文件
命名规则
我们从man手册对于make 指令的解释说明中,可知:
用户在编写makefile文件的时候,该文件的名称应该是makefile或者Makefile,建议大家使用Makefile作为该脚本文件的名称,注意:该文件是没有拓展名的!!!
基本规则
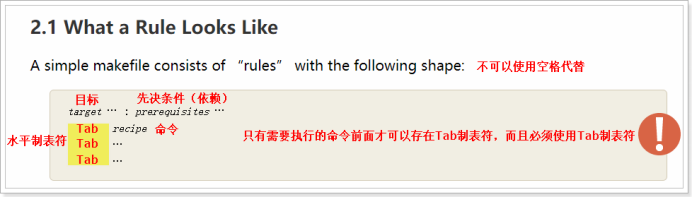
通过GNU组织提供的Make手册可以知道,Makefile文件的基本规则是有四部分组成,分别是目标、先决条件、制表符、命令,具体的规则如下所示:

注意:
- 一套完整的规则,目标、先决条件(依赖)、制表符、命令,四个部分缺一不可,但是根据实际情况,先决条件与shell命令可以不填写。
- Makefile中可以有多套规则存在,但是应该把最终目标的规则设置为第一套规则。
- 一个目标的多个依赖文件之间,使用<空格>隔开。
- 一个目标生成可能需要多条指令,但每条命令最好独立一行写,并且必须以Tab制表符开头;制表符的个数无强制要求,但是一般以一个Tab制表符开头。
- <tab符>即是制表符,即Tab键,*不能用空格代替*;也是因为这个制表符,make才知道后面是一个需要执行的shell命令。
- 如果想要在一行编写多条执行命令,则需要使用“;”分号将每条命令隔开。如无特殊情况,建议还是一条命令写一行。
- Makefile文件中允许存在“伪目标”,其意义为,如果不在make 后面添加指定伪目标名称,则不会执行伪目标内部的命令,一般多用于清除.o文件和可执行文件。“伪目标”如上图右边所示,且不能省略“.PHONY: 伪目标名称”。
- 经过实际测试,一个Makefile文件中不应该只存在伪目标,否则使用make时,会执行文件中的第一个伪目标。
- 如果make在执行Makefile中规则时,发现其依赖条件不存在,则会在Makefile文件中进行递归查找,该查找顺序与规则编写顺序无关,只要存在,make便会继续执行;没有找的则会报错。

Makefile文件实现原理进一步阐述
image:a.o b.o x.o y.o
gcc a.o b.o x.o y.o -o image
a.o:a.c
gcc a.c -o a.o -c
b.o:b.c
gcc b.c -o b.o -c
x.o:x.c
gcc x.c -o x.o -c
y.o:y.c
gcc y.c -o y.o -c
这个简单的Makefile文件总共有11行,具有5套规则,其中第1行中的image是第1个目标,冒号后面是这个目标的依赖列表(四个.o可重定位文件)。第2行的行首是一个制表符,后面紧跟着一句shell命令。
下面从第4行到第11行,也都是这样的“目标-依赖”,及其相关的Shell命令。但是这里必须注意一点:虽然这个Makefile总共出现了5个目标,但是第一个规则的目标(即image)被称之为终极目标,终极目标指的是当你执行make的时候,默认生成的那个可执行文件。
注意:如果第一个规则有多个目标,则只有第一个才是终极目标。另外,以圆点.开头的目标不在此讨论范围内,流程如下:
1.找到由终极目标构成的一套规则。(第1行和第2行)。
2.如果终极目标及其依赖列表都存在,则判断他们的时间戳关系,只要目标比任何一个依赖文件旧,就会执行其下面的Shell命令。(目标与执行命令中生成的可执行文件名要一致,否则无法对比依赖列表与目标的时间戳)
3.如果有任何一个依赖文件不存在,或者该依赖文件比该依赖文件的依赖文件要旧,则需要执行以该依赖文件为目标的规则的Shell命令。(比如a.o如果不存在或者比a.c要旧,则会找到a.o所在行的这一套规则,并执行其下一行的Shell命令)
4.如果依赖文件都存在并且都最新,但是目标不存在,则执行其下面的Shell命令。---对应执行文件不存在,make会生成的规则
变量说明
编写工程Makefile文件是为了简化编译流程的,但是目前编写的Makefile文件仍然不能满足该要求。
假设:在现有工程基础上再添加一个z.c源文件,要放在一起编译,对于上述的Makefile文件而言,可能需要重新修改一遍,另外,假设工程有1000个文件,貌似就要写1000套规则,这样是不现实的。其实Makefile提供了很多机制,比如变量、函数等来帮助我们更好更方便地组织工作(简化Makefile的编写)。
自定义变量
系统预定义变量
自动化变量
在Makefile中变量的特征有以下几点:
- 变量和函数的展开(除规则的命令行以外),是在make读取Makefile文件时进行的,这里的变量包括了使用“=”定义和使用指示符“define”定义的变量。
- 变量可以用来代表一个文件名列表、编译选项列表、程序运行的选项参数列表、搜索源文件的目录列表、编译输出的目录列表和所有我们能够想到的事物。这里需要与C语言中的变量作区分,不再是“容器”决定“承载内容”,而是“承载内容”决定“容器”。
- 变量名不能包括“:”、“#”、“=”、前置空白和尾空白的任何字符串。前置空白和尾空白会造成系统在执行相应命令的语法错误,且很难直接通过观察Makefile文件找出,需要特别注意。还需要注意的是,尽管在GNU make中没有对变量的命名有其它的限制,但定义一个包含除字母、数字和下划线以外的变量的做法也是不可取的,因为除字母、数字和下划线以外的其它字符可能会在以后的make版本中被赋予特殊含义,并且这样命名的变量对于一些Shell来说不能作为环境变量使用。
- 变量名是大小写敏感的。变量“foo”、“Foo”和“FOO”指的是三个不同的变量。Makefile传统做法是变量名是全采用大写的方式。推荐的做法是在对于内部定义的一般变量(例如:目标文件列表objects)使用小写方式,而对于一些参数列表(例如:编译选项CFLAGS)采用大写方式,这并不是要求的。但需要强调一点:对于一个工程,所有Makefile中的变量命名应保持一种风格,否则会显得你是一个蹩脚的开发者(就像代码的变量命名风格一样),随时有被鄙视的危险。
- 另外有一些变量名只包含了一个或者很少的几个特殊的字符(符号)。称它们为自动化变量。自动化变量也能够大幅度提升开发效率,像“<”、“@”、“?”、“*”、“@D”、“%F”、“^D”等等,通过深入的学习,我会将学习到的与大家一同分享。
- 变量的引用跟Shell脚本类似,使用美元符号和圆括号,比如有个变量叫A,那么对他的*引用则是$(A)*,有个自动化变量叫@,则对他的引用是$(@),有个系统变量是CC则对其引用的格式是$(CC)。对于前面两个变量而言,他们都是单字符变量,因此对他们引用的括号可以省略,写成$A和$@。 这点很重要,因为不按照“$(变量名)”系统将无法区别变量与普通文件名称,存在二义性。
变量种类介绍
1. 自定义变量
自定义变量,即用户定义的变量名称与变量中的内容,例如
A = apple
B = I love China
C = $(A) tree
以上三个变量都是自定义变量,其中变量A包含了一个单词,变量B的值包含了三个单词,变量C的值引用了变量A的值,因此他的值是“apple tree”。如果要将这三个变量的值打印出来,可以这么写:既然是类似宏,所以在使用是需要添加特殊符号的: $(变量名)
gec@ubuntu:~$ cat Makefile -n
1 A = apple
2 B = I love China
3 C = $(A) tree
4
5 all:
6 @echo $(A) //echo前面的@代表命令本身不打印出来
7 @echo $(B)
8 @echo $(C)
gec@ubuntu:~$ make
apple
I love China
apple tree
使用自定义变量,可以将前面的工程配置文件Makefile中的所有.o文件用一个变量OBJ来代表,这样可以减少输入代码量,且能够更好啊的对程序进行更新添加与减少,提升了可维护性:
gec@ubuntu:~$ cat Makefile -n
1 OBJ = a.o b.o x.o y.o
2
3 image:$(OBJ)
4 gcc $(OBJ) -o image
5
6 a.o:a.c
7 gcc a.c -o a.o -c
8 b.o:b.c
9 gcc b.c -o b.o -c
10 x.o:x.c
11 gcc x.c -o x.o -c
12 y.o:y.c
13 gcc y.c -o y.o -c
14 clean:
15 rm $(OBJ)
扩展介绍:“=” 、“ := ” 、“ ?= "、” += ” 四种赋值的区别
- 递归展开式变量:"="定义的变量是递归方式扩展的变量,在引用的地方是严格的文本替换过程,但在出现该变量的时候才会将他替换。例子如下:
A = $(B)
B = $(C)
C = banana
#在这里定义一个target伪目标
target: $(A)
echo $<
执行make指令后,最终会输出“banana”,实际输出过程如下:
将$(A)替换成$(B),
将$(B)替换成$(C),
将$(C)替换成banana,
最终打印出"banana"。
所以,使用"="定义的变量被称为“递归展开式变量“,即递归展开(一步步执行)。
- 直接展开式变量:在使用“:=”定义变量时,变量值中对其他量或者函数的引用在定义变量时被展开(对变量进行替换)。所以不能拿未定义的变量作为值(:= 右边的字符串)进行赋值动作。例子如下:
x := foo
y := $(x) bar
x := later
就等价于:
y := foo bar
x := later
和递归展开式变量不同:此风格变量在定义时就完成了对所引用变量和函数的展开,因此不能实现 对其后定义变量的引用。如:
CFLAGS := $(include_dirs)-O
include_dirs :=-Ifoo-Ibar
由于变量“include_dirs”的定义出现在“CFLAGS”定义之后。因此在“CFLAGS”的定义中, “include_dirs”的值为空。“CFLAGS”的值为“-O”而不是“-Ifoo-Ibar-O”。这一点也是直接展 开式和递归展开式变量的不同点。注意这里的两个变量都是“直接展开”式的。如果一个是“递归展开式”一个是“直接展开式”则情况又不一样。
- 追加变量值:"+="是一个通用变量,。我 们可以在定义时(也可以不定义而直接追加)给它赋一个基本值,后续根据需要可随时对它的值进 行追加(增加它的值)。在Makefile中使用“+=”(追加方式)来实现对一个变量值的追加操作。像 下边那样:当使用这种方式后,新赋值的变量值会添加到原有变量值的后面并用空格隔开。
objects += another.o
这个操作把字符串“another.o”添加到变量“objects”原有值的末尾,使用空格和原有值分开。 因此我们可以看到:
objects = main.o foo.o bar.o utils.o
objects += another.o
上边的两个操作之后变量“objects”的值就为:“main.o foo.o bar.o utils.o another.o”。使用 “+=”操作符,相当于:
objects = main.o foo.o bar.o utils.o
objects := $(objects) another.o
注意:
- 如果被追加值的变量之前没有定义,那么,“+=”会自动变成“=”,此变量就被定义为一个 递归展开式的变量。如果之前存在这个变量定义,那么“+=”就继承之前定义时的变量风格
- 直接展开式变量的追加过程:变量使用“:=”定义,之后“+=”操作将会首先替换展开之前 此变量的值,尔后在末尾添加需要追加的值,并使用“:=”重新给此变量赋值。
- 递归展开式变量的追加过程:一个变量使用“=”定义,之后“+=”操作时不对之前此变量 值中的任何引用进行替换展开,而是按照文本的扩展方式(之前等号右边的文本未发生变化) 替换,尔后在末尾添加需要追加的值,并使用“=”给此变量重新赋值。
-
条件赋值的赋值操作符“?=”。被称为条件赋值是因为:只有 此变量在之前没有赋值的情况下才会对这个变量进行赋值。例如:
FOO ?= bar其等价于:
ifeq ($(origin FOO), undefined) FOO = bar endif含义是:如果变量“FOO”在之前没有定义,就给它赋值“bar”。否则不改变它的值.
2. 系统预定义变量
CFLAGS、CC、MAKE、Shell等等,这些变量已经有了系统预定义好的值,当然我们可以根据需要重新给他们赋值,例如CC的默认值是gcc,当我们需要使用gcc编译器的时候可以直接使用。
这样做的好处是:在不同平台中,c编译器的名称也许会发生变化,如果我们的Makefile使用了100处c编译器的名字,那么换一个平台我们只需要重新给预定义变量CC赋值一次即可,而不需要修改100处不同的地方。比如我们换到ARM开发平台中,只需要重新给CC赋值为arm-linux-gcc即可。(用自定义变量覆盖系统预定义,实质是变量的值改变了,不再是原本的,而是一个新)
常用的系统预定义变量,请看下表:
| *变量名* | *含义* | *备注* |
|---|---|---|
| AR | 函数库打包程序,可创建静态库.a文档。默认是“ar”。 | 无 |
| AS | 汇编程序。默认是“as”。 | 无 |
| CC | C编译程序。默认是“cc”。 | 无 |
| CXX | C++编译程序。默认是“g++”。 | 无 |
| CPP | C程序的预处理器。默认是“$(CC) –E”。 | 无 |
| RM | 删除命令。默认是“rm –f”。 | 无 |
| ARFLAGS | 执行AR命令的命令行参数。默认值是“rv”。 | 无 |
| ASFLAGS | 汇编器AS的命令行参数(明确指定“.s”或“.S”文件时)。 | 无 |
| CFLAGS | 执行CC编译器的命令行参数(编译.c源文件的选项)。 | 无 |
| CXXFLAGS | 执行g++编译器的命令行参数(编译.cc源文件的选项)。 | 无 |
3. 自动化变量
<、@、?、#等等,这些特殊的变量之所以称为自动化变量,是因为它们的值会“自动地”发生变化,可以类比普通变量,只要你不给它重新赋值,那么它的值是永久不变的,比如上面的系统预定义CC变量,只要不对它重新赋值,CC永远都等于gcc。
也就是说自动化变量的值是可以改变的,不是固定的。例如@,不能说 @ 的值等于某个固定值,但是它的含义的固定的:*@* *代表了其所在规则的目标的完整名称*。
有关自动化变量的详细情况,见下表:
| *变量名* | *含义* | *备注* |
|---|---|---|
| *@* | *代表其所在规则的目标的完整名称* | |
| % | 代表其所在规则的静态库文件的一个成员名 | |
| *<* | *代表其所在规则的依赖列表的第一个文件的完整名称* | |
| ? | 代表所有时间戳比目标文件新的依赖文件列表,用空格隔开 | |
| *^* | *代表其所在规则的依赖列表* | *同一文件不可重复* |
| + | 代表其所在规则的依赖列表 | 同一文件可重复,主要用在程序链接时,库的交叉引用场合。 |
| * | 在模式规则和静态模式规则中,代表茎 | 茎是目标模式中“%”所代表的部分(当文件名中存在目录时,茎也包含目录(斜杠之前)部分。 |
上述列出的自动量变量中。其中有四个在规则中代表一个文件名(@、<、%和*)。而其它三个的在规则中代表一个文件名的列表。
其中在GUN make中,还可以通过以上这七个自动化变量来获取一个完整文件名中的目录部分或者具体文件名,需要在这些变量中加入“D”或者“F”字符。这样就形成了一系列变种的自动化变量:
| *变量名* | *含义* | *备注* |
|---|---|---|
| @D | 代表目标文件的目录部分(去掉目录部分的最后一个斜杠) | 如果“$@”是“dir/foo.o”,那么“$(@D)”的值为“dir”。如果“$@”不存在斜杠,其值就是“.”(当前目录)。注意它和函数“dir”的区别 |
| @F | 目标文件的完整文件名中除目录以外的部分(实际文件名) | 如果“$@”为“dir/foo.o”,那么“$(@F)”只就是“foo.o”。“$(@F)”等价于函数“$(notdir $@)” |
| *D | 代表目标茎中的目录部分 | |
| *F | 代表目标茎中的文件名部分 | |
| %D | 当以如“archive(member)”形式静态库为目标时,表示库文件成员“member”名中的目录部分 | 仅对“archive(member)”形式的规则目标有效 |
| %F | 当以如“archive(member)”形式静态库为目标时,表示库文件成员“member”名中的文件名部分 | 仅对“archive(member)”形式的规则目标有效 |
| <D | 代表规则中第一个依赖文件的目录部分 | |
| <F | 代表规则中第一个依赖文件的文件名部分 | |
| ^D | 代表所有依赖文件的目录部分 | 同一文件不可重复 |
| ^F | 代表所有依赖文件的文件名部分 | 同一文件不可重复 |
| +D | 代表所有依赖文件的目录部分 | 同一文件可重复 |
| +F | 代表所有依赖文件的文件名部分 | 同一文件可重复 |
| ?D | 代表被更新的依赖文件的目录部分。 | |
| ?F | 代表被更新的依赖文件的文件名部分。 |
静态规则
所谓的静态规则,其工作原理是:$(OBJ)被称为原始列表,即(a.o b.o x.o y.o),紧跟在其后的%.o被称为匹配模式,含义是在原始列表中按照这种指定的模式挑选出能匹配得上的单词(在本例中要找出原始列表里所有以.o为后缀的文件)作为规则的目标。如下所示:
gec@ubuntu:~$ cat Makefile -n
1 OBJ = a.o b.o c.o
2
3 image:$(OBJ)
4 $(CC) $(OBJ) -o image
5
6 $(OBJ):%.o:%.c
7 $(CC) $(^) -o $(@) l -c -Wal
8
9 clean:
10 $(RM) $(OBJ) image
11
12 .PHONY: clean
静态规则工作原理整个过程用下图演示:
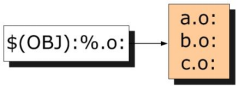
简单地讲,就是用一个规则来生成一系列的目标文件。接着,第二个冒号后面的内容就是目标对应的依赖,%可以理解为通配符,因此本例中%.o:%.c的意思就是:每一个匹配出来的目标所对应的依赖文件是同名的.c文件,这个过程也用图演示如下:
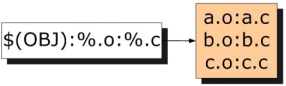
可见,静态规则的目的就是用一句话来自动生成很多目标及其依赖,接下来要针对每一对目标-依赖生成对应的编译语句:
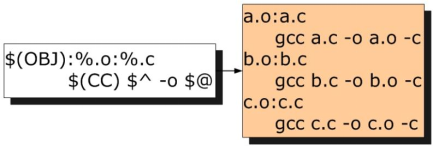
此处可见自动化变量的用武之地了,因为每一对目标-依赖对的名字都不一样,因此在静态规则中不可能直接把名字写死,而要用自动化变量来自动调整为对应的名字。
总结一下,静态规则是:当规则存在多个目标时,不同的目标可以根据目标文件的名字来自动构造出依赖文件(即只需写出目标名,即可寻找相应同名字的依赖文件)。
热门相关:超萌迷糊妻:BOSS大人别这样 弃妃不承欢:腹黑国师别乱撩 无法忍受的性游戏 霸道女皇爱上我 隐婚99天:首席,请矜持