掌握pandas cut函数,一键实现数据分类
pandas中的cut函数可将一维数据按照给定的区间进行分组,并为每个值分配对应的标签。
其主要功能是将连续的数值数据转化为离散的分组数据,方便进行分析和统计。
1. 数据准备
下面的示例中使用的数据采集自王者荣耀比赛的统计数据。
数据下载地址:https://databook.top/。
导入数据:
# 2023年世冠比赛选手的数据
fp = r"D:\data\player-2023世冠.csv"
df = pd.read_csv(fp)
# 这里只保留了下面示例中需要的列
df = df.loc[:, ["排名", "选手", "场均经济", "场均伤害"]]
df

2. 使用示例
每个选手的“场均经济”和“场均伤害”是连续分布的数据,为了整体了解所有选手的情况,
可以使用下面的方法将“场均经济”和“场均伤害”分类。
2.1. 查看数据分布
首先,可以使用直方图的方式看看数据连续分布的情况:
import matplotlib.pyplot as plt
df.loc[:, ["场均经济", "场均伤害"]].hist()
plt.show()
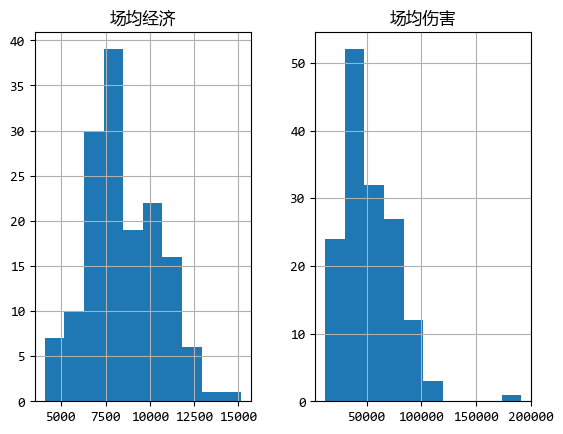
图中的横轴是“经济”和“伤害”的数值,纵轴是选手的数量。
2.2. 定制分布参数
从默认的直方图中可以看出大部分选手的“场均经济”和“场均伤害”大致在什么范围,
不过,为了更精细的分析,我们可以进一步定义自己的分类范围,看看各个分类范围内的选手数量情况。
比如,我们将“场均经济”分为3块,分别为低(0~5000),中(5000~10000),高(10000~20000)。
同样,对于“场均伤害”,也分为3块,分别为低(0~50000),中(50000~100000),高(100000~200000)。
bins1 = [0, 5000, 10000, 20000]
bins2 = [0, 50000, 100000, 200000]
labels = ["低", "中", "高"]
s1 = "场均经济"
s2 = "场均伤害"
df[f"{s1}-分类"] = pd.cut(df[s1], bins=bins1, labels=labels)
df[f"{s2}-分类"] = pd.cut(df[s2], bins=bins2, labels=labels)
df

分类之后,选手被分到3个类别之中,然后再绘制直方图。
df.loc[:, f"{s1}-分类"].hist()
plt.title(f"{s1}-分类")
plt.show()

从这个图看出,大部分选手都是“中”,“高”的经济,说明职业选手很重视英雄发育。
df.loc[:, f"{s2}-分类"].hist()
plt.title(f"{s2}-分类")
plt.show()

从图中可以看出,打出高伤害的选手比例并不高,可能职业比赛中,更多的是团队作战。
3. 总结
总的来说,cut函数的主要作用是将输入的数值数据(可以是一维数组、Series或DataFrame的列)按照指定的间隔或自定义的区间边界进行划分,并为每个划分后的区间分配一个标签。
这样,原始的连续数据就被转化为了离散的分组数据,每个数据点都被分配到了一个特定的组中,从而方便后续进行分析和统计。
热门相关:甜蜜隐婚:老公大人,宠上瘾 上古传人在都市 盛华 妖夏 第一强者