别再低效筛选数据了!试试pandas query函数
数据过滤在数据分析过程中具有极其重要的地位,因为在真实世界的数据集中,往往存在重复、缺失或异常的数据。pandas提供的数据过滤功能可以帮助我们轻松地识别和处理这些问题数据,从而确保数据的质量和准确性。
今天介绍的query函数,为我们提供了强大灵活的数据过滤方式,有助于从复杂的数据集中提取有价值的信息,提高分析的效率。
1. 准备数据
下面的示例中使用的数据采集自链家网的真实房屋成交数据。
数据下载地址:https://databook.top/。
导入数据:
import pandas as pd
fp = "D:/data/南京二手房交易/南京建邺区.csv"
df = pd.read_csv(fp)
df.head()

2. query 使用示例
query提供的查询接口非常灵活,可以用类似sql的方式组合查询条件。
2.1. 比较
比较是最常用的过滤手段,
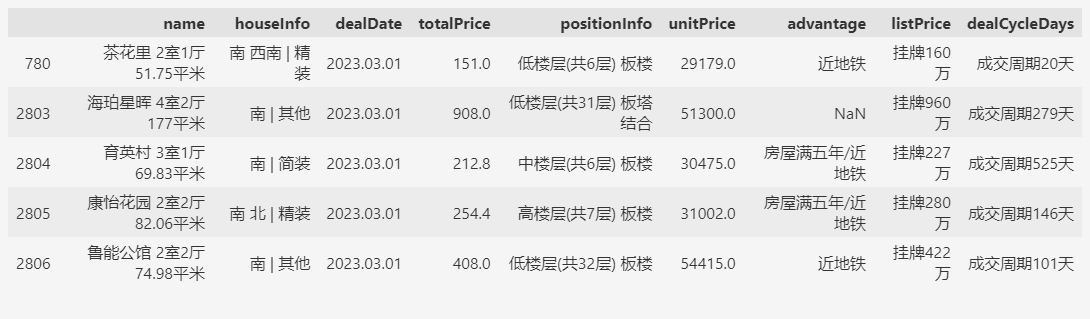
比如:相等比较,检索2023年3月1日的成交数据。
df.query('dealDate == "2023.03.01"').head()
同样,也可以进行大于或者小于的比较:
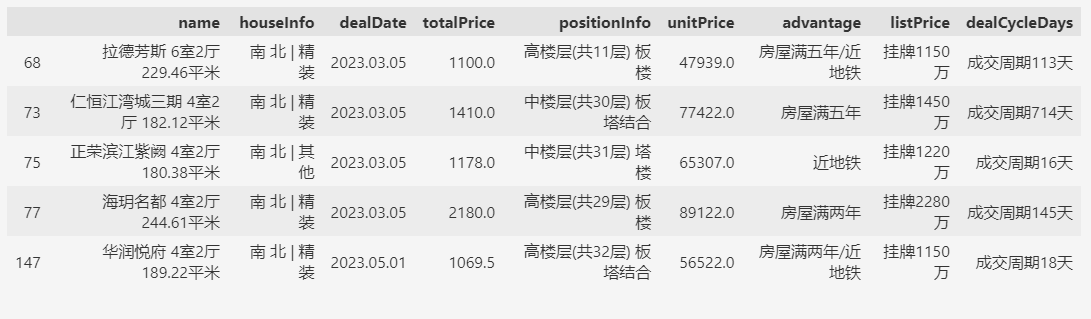
# 成交总价大于1000万的房屋
df.query('totalPrice > 1000').head()
# 成交总价小于100万的房屋
df.query('totalPrice < 100').head()

2.2. 多条件组合
在query函数中组合查询条件也非常简单,它的查询字符串中可以直接使用逻辑运算符。
比如,逻辑与的查询,用 & 来连接查询条件。
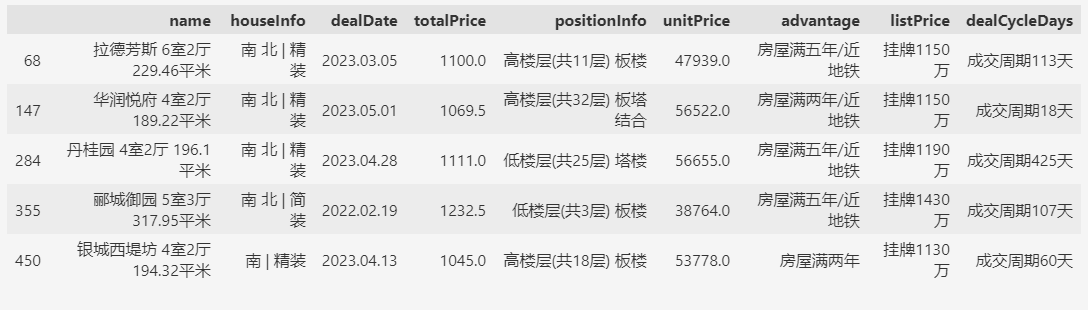
# 总价大于1000万,且每平米单价小于6万的房屋
df.query('totalPrice > 1000 & unitPrice < 60000').head()
逻辑或的查询,用|来连接查询条件。
# 总价小于200万,或者每平米单价小于3万的房屋
df.query('totalPrice < 200 | unitPrice < 30000').head()

因为是逻辑或,两个条件满足一个就行,所以查询出的数据有总价大于200万,也有单价大于3万的数据。
还有一个逻辑非的运算,用 not 关键字来表示。
2.3. 模糊查询
除了比较,也可以对字符串进行模糊查询,类似sql中的LIKE检索。
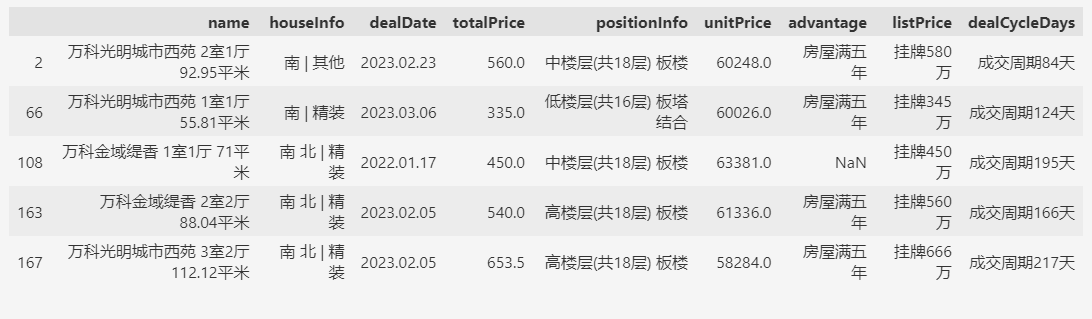
比如,查询名称包含万科的楼盘。
# 名称包含万科
df.query('name.str.contains("万科")').head(5)
包含的字符串也支持正则表达式匹配,比如,查询万科楼盘中3室的房屋。
df.query('name.str.contains("万科.*3室")').head(5)

2.4. 匹配列表
查询时,可以匹配某个列表中的一项,类似于SQL中的IN检索。
比如,查询任意三个日期的房屋成交信息,且总价大于500万。
dates = ["2023.02.28", "2022.12.11", "2022.04.10"]
df.query('totalPrice > 600 & dealDate == @dates').head(5)

3. 总结
pandas的DataFrame提供了各种过滤检索数据的方式,与之相比,query函数允许用户以字符串的形式对DataFrame进行查询操作。
这样的好处有:
- 直观易读:类似SQL的语法,且查询语句以字符串形式表示,易于理解和阅读,有助于提高代码的可读性
- 灵活性高:支持复杂的查询条件,可以通过逻辑运算符组合多个条件,也支持模糊的匹配方式
- 减少代码量:可以减少编写过滤和条件判断的代码量,使代码更加简洁
- 易于调试:由于查询语句以字符串形式表示,因此在调试过程中可以轻松地打印和查看查询条件
热门相关:北宋大表哥 庶子风流 名门贵妻:暴君小心点 1号婚令:早安,大总裁! 明朝败家子