【进阶篇】使用 Redis 实现分布式缓存的全过程思考(一)
前言
写在前面,让我们从 3 个问题开始今天的文章:什么是 Redis 缓存?它解决了什么问题?怎么使用它?
在笔者近 3 年的 Java 一线开发经历中,尤其是一些移动端、用户量大的互联网项目,经常会使用到 Redis 分布式缓存作为解决高并发的基本工具。但在使用过程中也有一些潜在的问题是必须要考虑的,比如:数据一致性、缓存穿透和雪崩、高可用集群等等。
下面我就将从关于缓存是什么、项目中的实现、数据一致性等这几个方面来分享一下我自己是怎么使用 Redis 实现分布式缓存的。
一、关于缓存
缓存分为本地缓存和分布式缓存。以 Java 为例,使用自带的 map 或者 guava 实现的是本地缓存,最主要的特点是轻量以及快速,生命周期随着 JVM 的销毁而结束,且在多实例的情况下本地缓存不具有一致性。
而使用 Redis 或 memcached 之类的称为分布式缓存。在多实例(集群)的情况下,Redis 的事务会一次性、顺序性、排他性地执行队列中的一系列命令,各实例共用一份缓存数据,缓存具有一致性。
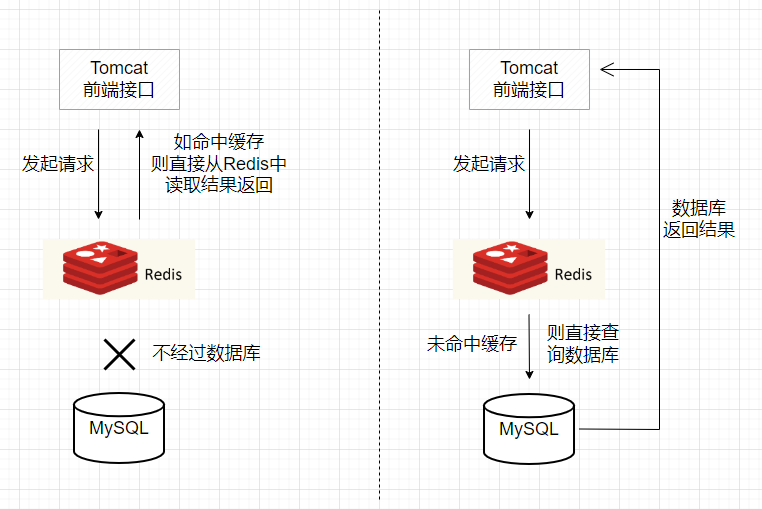
用户第一次访问数据库的数据,因为是从硬盘上读取的所以比较慢。将该用户访问的数据存在缓存中,这样下一次再访问这些数据的时候就可以直接从缓存中获取了。如果数据库中的对应数据改变的之后,同步改变缓存中相应的数据即可,这里涉及到的数据一致性问题会在第四小节专门讲。
至于 Redis 为什么这么快,最主要有以下几个原因:
- 完全基于内存,绝大部分请求是纯粹的内存操作,速度非常地快;
- 采用单线程,避免了不必要的上下文切换和竞争条件,不存在因多线程的切换而消耗 CPU;也不存在加锁、释放锁操作,也没有因死锁而导致的性能消耗;
- 使用多路 I/O 复用模型(很关键),非阻塞的 IO,能让单个线程高效地处理多个连接请求,尽量减少网络 IO 的时间消耗。

注:X 轴为客户端连接数,Y 轴是 QPS。即在近一万的客户端连接下,还能达到近十万的 QPS,这样强悍的性能是 MySQL 无法企及的。
二、基本数据结构
众所周知,直接操作缓存能够承受的请求是远远大于直接访问数据库的,所以我们可以考虑把数据库中的部分数据(热点数据、读多写少的数据)转移到缓存中去,这样用户的一部分请求会直接到缓存这里而不用经过数据库。
Redis 有 5 种基本的数据结构,具体参考我的另一篇博客:https://www.cnblogs.com/CodeBlogMan/p/17816699.html
三、缓存注解
用于后端接口的数据缓存,加在接口的实现方法上,这是我在实际项目中处理高并发的基本做法之一。说到注解,那么就需要从以下几个必不可少的方面进行展开。
3.1自定义注解
@Retention(RetentionPolicy.RUNTIME)
@Target({ElementType.METHOD, ElementType.TYPE})
@Inherited
public @interface Cache {
/**
* 缓存 key 默认为空串,会根据调用的类签名自动生成
* 如果指定 key,则使用指定的 key
* @return redis key
*/
String key() default "";
/**
* 超时时间,默认 3 秒
* @return redis 的超时时间
*/
int expiryTime() default 3;
}
3.2定义切点(拦截器)
- 在 AOP 中,Joinpoint 代表了程序执行的某个具体位置,比如方法的调用、异常的抛出等。AOP 框架通过拦截这些 Joinpoint 来插入额外的逻辑,实现横切关注点的功能。
- 而实现拦截器 MethodInterceptor 接口比较特殊,它会将所有的 @AspectJ 定义的通知最终都交给 MethodInvocation(子类 ReflectiveMethodInvocation )去执行。
public class CacheAnnotationInterceptor extends CacheAop implements MethodInterceptor {
public CacheAnnotationInterceptor(ICache iCache) {
// 调用父类有参构造
super(iCache);
}
public CacheAnnotationInterceptor(RedisTemplate<Object, Object> redisTemplate) {
// 调用父类有参构造
super(redisTemplate);
}
/**
* 反射实现,通过拦截方法的执行来实现通知的效果
* @param methodInvocation
* @return
* @throws Throwable
*/
@Override
public Object invoke(MethodInvocation methodInvocation) throws Throwable {
// 即下面父类的具体 AOP 实现
return super.cacheAop(methodInvocation);
}
}
3.3 AOP 实现
下面的 AOP 仅是大致过程,思路用注释写得比较清楚了,完整的代码有时间脱敏后再分享吧。
/**
* 子类 CacheAnnotationInterceptor 重写了 MethodInterceptor 的 invoke() 方法
*/
public class CacheAop {
/**
* 基于 Redis 的一些常见 API 实现
*/
protected ICache iCache;
protected RedisTemplate<Object, Object> redisTemplate;
public CacheAop(ICache iCache) {
this.iCache = iCache;
}
public CacheAop(RedisTemplate<Object, Object> redisTemplate) {
this.redisTemplate = redisTemplate;
}
/**
* 缓存切面实现
*/
public Object cacheAop(MethodInvocation methodInvocation) throws Throwable {
// 检查是否使用缓存
if (this.isUseCache(methodInvocation)) {
// 自定义缓存注解
Cache cache = methodInvocation.getMethod().getAnnotation(Cache.class);
// 生成缓存的 key
String key = this.generateCacheKey(cache, methodInvocation);
// 缓存操作
return this.handlerCache(key, cache, methodInvocation);
} else {
// 需要执行的时候,调用.proceed()方法即可
return methodInvocation.proceed();
}
}
}
3.4使用示例
下面是一个简单示例,@Cache 注解加在需要缓存的方法上,设置过期时间为 5 秒。即 5 秒内调用该方法,返回的数据是来自缓存,过期后会再次从数据库中获取,并重新写入缓存,循环往复。
/**
* 根据 Id 从缓存中查询详情
* @param id
* @return
*/
@Cache(expiryTime = 5)
public Study getDetailByIdFromCache(String id) {
return Optional.of(this.studyMapper.selectById(id)).orElse(null);
}
四、数据一致性
数据库一旦引入了其它组件,必然会带来数据一致性的问题。这里不考虑强一致性,因为强一致性引发的性能问题在高并发的情景下是不可接受的。所以只考虑最终一致性。
4.1缓存更新策略
一般来说,为了保证数据一致性,会有 3 种常见的 Redis 缓存更新策略,如下表所示:
| 策略 | 描述 | 一致性 | 维护成本 |
|---|---|---|---|
| 内存淘汰 | 无需自己维护,Redis 自己有内存淘汰机制,当内存不足时会淘汰部分,下次查询时再更新缓存。 | 差 | 无 |
| 超时剔除 | 为缓存数据添加生存时间 TTL(Time To Live),到期后自动删除缓存,下次查询时再更新缓存。 | 一般 | 低 |
| 主动更新 | 额外编写代码逻辑,在修改数据库数据的同时,更新缓存。 | 好 | 高 |
我自己在项目是选择超时剔除和主动更新这 2 种方法搭配使用的,在合适的时候用合适的办法。
前者适合在对实时性要求不那么高的情况下使用,后者适合在对实时性要求较高的场景使用。至于内存淘汰是不可能会用的,太傻瓜了,放到线上 100% 出问题。
超时剔除的核心逻辑:缓存来源于数据库,到过期时间后,缓存中的数据会被删除;用户再次请求的就是数据库的数据,再把数据库数据重新放入到缓存,依次反复。
主动更新的核心逻辑:缓存操作一定不能和数据库事务作为一个大事务来处理,尤其是在较复杂的业务流程中,一般都是先完成数据库的事务操作后,再去操作缓存中的数据。
4.2缓存读写过程
具体读和写分为以下两点:
-
对于读操作,一般都是先读取缓存,如果命中则返回;没有命中则去读数据库返回数据,这个逻辑很好理解,也没什么争议。
-
对于写操作,有两个需要考虑的问题:
-
如何更新缓存,是删除缓存还是修改缓存?
答:设置过期时间,直接删。不必要再去修改之前的缓存数据
-
是先更新数据库还是先更新缓存?
答:先更新数据库,再更新缓存
-
如果更新完了数据库,但是之前的缓存删除失败,读的依然是旧数据怎么办?
答:设置较短的缓存时间,短时间内再次删除缓存。
-
如果数据库是主从结构,即 master 负责事务操作,slave 只负责读,数据同步的延迟影响到缓存的更新怎么办?
答:考虑从硬件下手,提升数据库性能 + 提升网络带宽。
-
-
五、高可用
5.1缓存穿透
缓存穿透:是指客户端请求的数据在缓存中和数据库中都不存在,那么缓存永远不会生效。这样,每次针对此 key 的请求从缓存获取不到,请求都会压到数据源,从而可能压垮数据源。此时,缓存起不到保护后端持久层的意义,就像被穿透了一样。
以下是常用的缓存穿透的解决方案:
-
对空值进行缓存:即使一个查询返回的数据为空,仍然把这个空结果(null)进行缓存,同时还可以对空结果设置较短的过期时间。这种方法实现简单,维护方便,但是会额外的内存消耗。
-
采用布隆过滤器:(布隆过滤器(Bloom Filter)是 1970 年由布隆提出的。它实际上是一个很长的二进制向量(位图)和一系列随机映射函数(哈希函数)。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难。
-
加强 id 复杂度(如雪花和 UUID)和参数校验,比如保证要查询的 key 不为负数或者非法字符串
-
加强用户权限校验:对页面操作加以限制,对接口的调用进行鉴权。
5.2缓存击穿
缓存击穿:是指某个热点 key,在缓存过期的一瞬间有大量的请求进来,由于此时缓存刚好过期,所以请求最终都会走数据库,数据库压力瞬间骤增,导致数据库存在被打挂的风险。这样的情况下,彷佛缓存被请求给击穿了。
应该这种情况主要的解决方案如下:
- 加互斥锁。当热 key 过期大量的请求涌入时,只有第一个请求能获取锁并阻塞,此时保证该请求查询数据库,并将查询结果写入 redis 缓存后释放锁,则后续的请求直接走缓存。
以下是一个通用解决方案的大致思路,可以兼顾处理缓存穿透和击穿问题。至于下面提到的“给 Key 设置合理的 TTL 并加上随机值”,这个也比较好实现。
protected Object handleCache(String key, Cache cache, MethodInvocation invocation) throws Throwable {
//设置 key 到 ThreadLocal 中,方便使用
KeyThreadLocalUtils.setValue(key);
//双重检查,防止高并发情况下因为缓存失效导致的缓存穿透问题
Object value = this.getValueForCache(key);
if (Objects.isNull(value)) {
//加锁,防止缓存击穿
synchronized (DigestUtils.md5Hex(key).intern()) {
logger.info("方法为:{},key为:{}", invocation.getMethod().getName(), key);
value = this.getValueForCache(key);
//对空值也进行缓存
if (Objects.isNull(value)) {
value = invocation.proceed();
if (value instanceof Serializable) {
this.setValueToCache(key, value, cache.expiryTime());
} else {
logger.warn("方法{}使用了缓存注解,但返回对象{}未序列化", invocation.getMethod().getName(), value);
}
}
}
}
KeyThreadLocalUtils.removeValue();
return value;
}
5.3缓存雪崩
缓存雪崩:是指由于大量的缓存 key 的过期时间相同,导致数据在同一时刻集体失效,或者 Redis 服务宕机,导致大量请求到达数据库,给数据库带来巨大压力。这种情况通常是由于缓存时间设置不当,或者缓存容量不足引起的。
以下是常用的缓存雪崩的解决方案:
-
给 Key 设置合理的 TTL 并加上随机值
-
增加缓存容量
-
给缓存业务添加降级限流策略
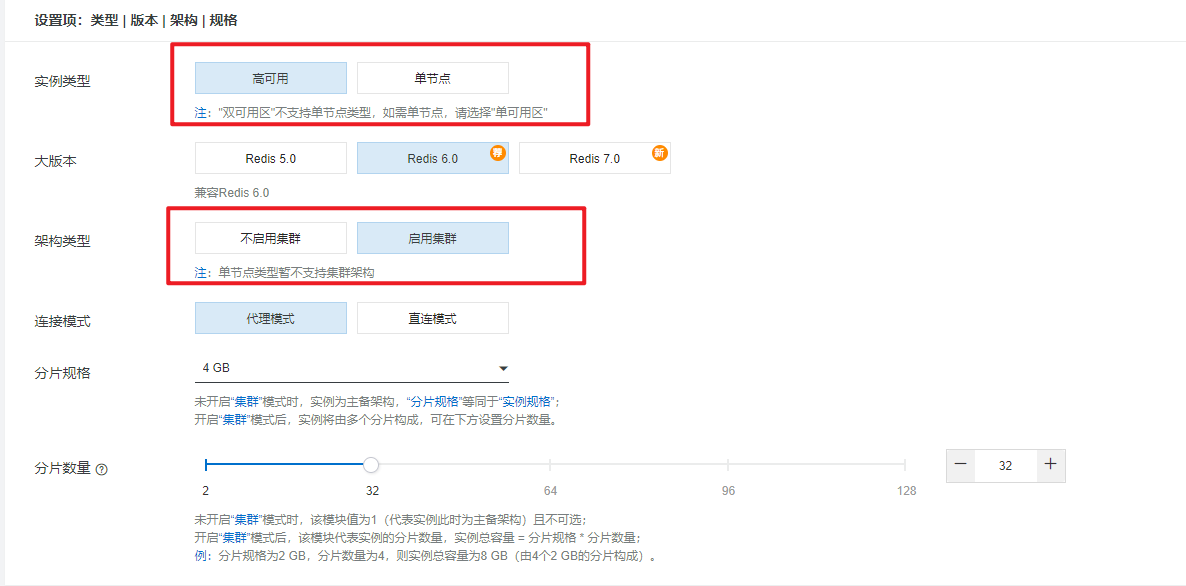
5.4Redis 集群
在硬件层面,通过购买云服务厂商的 Redis 集群来保证服务的高可用。以下拿阿里云云数据库 Redis 的一些基本配置来举例:
六、文章小结
到这里关于使用 Redis 实现分布式缓存的全过程就分享完了,其实关于 redis 缓存的高可用部分还有许多能详细展开的地方。但是目前我对于缓存的击穿、穿透和雪崩没有太多的实际场景来分享,更多的是一种学习和储备。
最后,如果文章有不足和错误,还请大家指正。或者你有其它想说的,也欢迎大家在评论区交流!
热门相关:总裁大人,又又又吻我了 娇妻如云 玉堂金闺 北宋闲王 护花猎王