Springboot集成MongoDB存储文件、读取文件
一、前言和开发环境及配置
可以转载,但请注明出处。
之前自己写的SpringBoot整合MongoDB的聚合查询操作,感兴趣的可以点击查阅。
https://www.cnblogs.com/zaoyu/p/springboot-mongodb.html
使用mongodb存储文件并实现读取,通过springboot集成mongodb操作。
可以有两种实现方式:
1. 单个文件小于16MB的,可以直接把文件转成二进制或者使用如Base64编码对文件做编码转换,以二进制或者string格式存入mongodb。
读取时,把二进制数据或者string数据转成对应的IO流或做解码,再返回即可。
2. 对于单个文件大于16MB的,可以使用mongodb自带的GridFS
开发环境、工具:JDK1.8,IDEA 2021
Springboot版本:2.7.5
Mongodb依赖版本:4.6.1
SpringBoot的配置 application.properties 如下
# 应用名称 spring.application.name=demo #server.port=10086 不配置的话,默认8080 # springboot下mongoDB的配置参数。 spring.data.mongodb.host=localhost spring.data.mongodb.port=27017 # 指定数据库库名 spring.data.mongodb.database=temp
二、实现步骤和代码
1. 小文件存储
1.1 说明和限制
由于MongoDB限制单个文档大小不能超过16MB,所以这种方式仅适用于单个文件小于16MB的。
如果传入大于16MB的文件,存储是会失败的,报错如下。

1.2 实现代码
package com.onepiece.mongo; import org.bson.Document; import org.bson.types.Binary; import org.junit.jupiter.api.Test; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.boot.test.context.SpringBootTest; import org.springframework.data.mongodb.core.MongoTemplate; import org.springframework.data.mongodb.core.query.Criteria; import org.springframework.data.mongodb.core.query.Query; import java.io.*; import java.util.Base64; import java.util.List; /** * @author zaoyu * @description 用于演示Mongodb的文件存储(单个文件不大于16MB) */ @SpringBootTest public class MongoSaveFiles { @Autowired private MongoTemplate mongoTemplate; // collection名 private String IMAGE_COLLECTION = "image"; // 源文件完整路径 private String FILE_PATH = "D:\\temp\\onepiece.jpg"; // 输出文件路径 private String FILE_OUTPUT_PATH = "C:\\Users\\onepiece\\Desktop\\"; // 限制16MB private Long FILE_SIZE_LIMIT = 16L * 1024L * 1024L; @Test public void saveFiles(){ byte[] fileContent = null; FileInputStream fis = null; try { File file = new File(FILE_PATH); long length = file.length(); // 校验文件大小,大于16MB返回。 这里的操作逻辑依据你自己业务需求调整即可。 if (length >= FILE_SIZE_LIMIT) { System.out.println("文件: " + file.getAbsolutePath() + " 超出单个文件16MB的限制。" ); return; } fileContent = new byte[(int) file.length()]; fis = new FileInputStream(file); // 读取整个文件 fis.read(fileContent); // 把文件内容以二进制格式写入到mongodb Document document = new Document(); // fileName字段、content字段自定义。 document.append("fileName", file.getName()); document.append("content", new Binary(fileContent)); Document insert = mongoTemplate.insert(document, IMAGE_COLLECTION); System.out.println("文件 " + file.getName() + " 已存入mongodb,对应ID是: " + insert.get("_id").toString()); } catch (IOException e) { e.printStackTrace(); } finally { try { fis.close(); } catch (IOException e) { e.printStackTrace(); } } } /** * 测试读取并写入到指定路径。 */ @Test public void readAndWriteFiles(){ // 这里也是,默认查所有,需要条件自行增加。 简单取1条验证。 List<Document> result = mongoTemplate.find(new Query(), Document.class, IMAGE_COLLECTION); Document document = result.get(0); // 取出存储的二进制数据,这里用binary.class处理。 Binary content = document.get("content", Binary.class); String fileName = document.get("fileName", String.class); try { String newFilePath = FILE_OUTPUT_PATH + fileName; // 写入到指定路径 FileOutputStream fos = new FileOutputStream(newFilePath); fos.write(content.getData()); } catch (IOException e) { e.printStackTrace(); } }
除了二进制的格式,也可以直接把文件用如Base64之类的编码工具来转码存储String。
@Test public void testBase64(){ saveFileWithBase64(FILE_PATH); getFileWithBase64(); } public void saveFileWithBase64(String filePath){ // 读取文件并编码为 Base64 格式 File file = new File(filePath); byte[] fileContent = new byte[(int) file.length()]; try (FileInputStream inputStream = new FileInputStream(file)) { inputStream.read(fileContent); } catch (IOException e) { e.printStackTrace(); } // 把读取到的流转成base64 String encodedString = Base64.getEncoder().encodeToString(fileContent); // 将 Base64 编码的文件内容存储到 MongoDB 文档中 Document document = new Document(); document.put("fileName", file.getName()); document.put("base64Content", encodedString); Document insert = mongoTemplate.insert(document, IMAGE_COLLECTION); System.out.println("文件 " + file.getName() + " 已存入mongodb,对应ID是: " + insert.get("_id").toString()); } public void getFileWithBase64(){ Criteria criteria = Criteria.where("base64Content").exists(true); List<Document> result = mongoTemplate.find(new Query(criteria), Document.class, IMAGE_COLLECTION); Document document = result.get(0); String base64Content = document.get("base64Content", String.class); String fileName = document.get("fileName", String.class); byte[] decode = Base64.getDecoder().decode(base64Content); try { String newFilePath = FILE_OUTPUT_PATH + fileName; FileOutputStream fos = new FileOutputStream(newFilePath); fos.write(decode); System.out.println("文件已读取并复制到指定路径,详情为:" + newFilePath); } catch (IOException e) { e.printStackTrace(); } }
1.3 落库效果
直接存储二进制数据,可以看到,使用BinData存储,还会显示字节数(文件大小)。

2. 大于16MB的文件存储,使用GridFS
2.1 gridFS简介
GridFS is a specification for storing and retrieving files that exceed the BSON-document size limit of 16 MB.
字面直译就是说GridFS是用来存储大于BSON文档限制的16MB的文件。
官方文档 https://www.mongodb.com/docs/manual/core/gridfs/
存储原理:GridFS 会将大文件对象分割成多个小的chunk(文件片段), 一般为256k/个,每个chunk将作为MongoDB的一个文档(document)被存储在chunks集合中。
每一个数据库有一个GridFS区域,用来存储。
需要通过先创建bucket(和OSS中一样的概念)来存储,一个bucket创建后,一旦有文件存入,在collections中就会自动生成2个集合来存储文件的数据和信息,一般是bucket名字+files和bucket名字+chunks。
每个文件的实际内容被存在chunks(二进制数据)中,和文件有关的meta数据(filename,content_type,还有用户自定义的属性)将会被存在files集合中。
如下图结构

2.2 实现代码
package com.onepiece.mongo; import com.mongodb.client.MongoDatabase; import com.mongodb.client.gridfs.GridFSBucket; import com.mongodb.client.gridfs.GridFSBuckets; import com.mongodb.client.gridfs.model.GridFSUploadOptions; import org.bson.Document; import org.bson.types.ObjectId; import org.junit.jupiter.api.Test; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.boot.test.context.SpringBootTest; import org.springframework.data.mongodb.core.MongoTemplate; import org.springframework.data.mongodb.core.query.Query; import org.springframework.util.FileCopyUtils; import java.io.*; import java.util.List; /** * @author zaoyu * @description:使用GridFS存储文件并做读取。 */ @SpringBootTest public class MongoGridFS { @Autowired private MongoTemplate mongoTemplate; // GridFS下的bucket,自行指定要把文件存储到哪个bucket。 private String BUCKET_NAME = "images"; // 源文件,即要被存储的文件的绝对路径 private String FILE_PATH = "D:\\temp\\onepiece.jpg"; // 存储文件后自动生成的存储文件信息的collection,一般是xx.files。 private String COLLECTION_NAME = "images.files"; // 用于演示接收输出文件的路径 private String FILE_OUTPUT_PATH = "C:\\Users\\onepiece\\Desktop\\"; @Test public void testGridFSSaveFiles() { saveToGridFS(); System.out.println("------------"); readFromGridFS(); } /** * 传入bucketName得到指定bucket操作对象。 * * @param bucketName * @return */ public GridFSBucket createGridFSBucket(String bucketName) { MongoDatabase db = mongoTemplate.getDb(); return GridFSBuckets.create(db, bucketName); } /** * 储存文件到GridFS */ public void saveToGridFS() { // 先调用上面方法得到一个GridFSBucket的操作对象 GridFSBucket gridFSBucket = createGridFSBucket(BUCKET_NAME); File file = new File(FILE_PATH); FileInputStream inputStream = null; try { inputStream = new FileInputStream(file); } catch (FileNotFoundException e) { e.printStackTrace(); } // 设置GridFS存储配置,这里是设置了每个chunk(块)的大小为1024个字节,也可以设置大一点。 MetaData是对文件的说明,如果不需要可以不写。 也是以键值对存在,BSON格式。 GridFSUploadOptions options = new GridFSUploadOptions().chunkSizeBytes(1024).metadata(new Document("user", "onepiece")); // 调用GridFSBucket中的uploadFromStream方法,把对应的文件流传递进去,然后就会以binary(二进制格式)存储到GridFS中,并得到一个文件在xx.files中的主键ID,后面可以用这个ID来查找关联的二进制文件数据。 ObjectId objectId = gridFSBucket.uploadFromStream(file.getName(), inputStream, options); System.out.println(file.getName() + "已存入mongodb gridFS, 对应id是:" + objectId); } /** * 从GridFS中读取文件 */ public void readFromGridFS() { // 这里查找条件我先不写,默认查所有,取第一条做验证演示。 用Document类接收。 List<Document> files = mongoTemplate.find(new Query(), Document.class, COLLECTION_NAME); Document file = files.get(0); // 得到主键ID,作为等下要查询的文件ID值。 ObjectId fileId = file.getObjectId("_id"); String filename = file.getString("filename"); // 先调用上面方法得到一个GridFSBucket的操作对象 GridFSBucket gridFSBucket = createGridFSBucket(BUCKET_NAME); // 调用openDownloadStream方法得到文件IO流。 InputStream downloadStream = gridFSBucket.openDownloadStream(fileId); FileOutputStream fileOutputStream = null; try { fileOutputStream = new FileOutputStream(FILE_OUTPUT_PATH + filename); // 把IO流直接到指定路径的输出流对象实现输出。 FileCopyUtils.copy(downloadStream, fileOutputStream); } catch (IOException e) { e.printStackTrace(); } finally { try { fileOutputStream.close(); } catch (IOException e) { e.printStackTrace(); } } } }
2.3 落库效果
bucket:

注意这里的ID,就是files中的主键ID。
files collection (image.files):

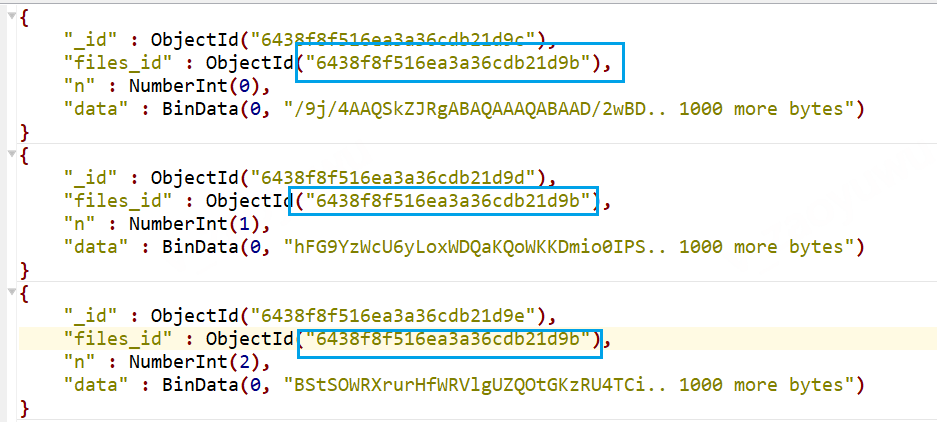
chunks collection (image.chunks)
可以看到这里的files_id就是对应image.files中的主键ID。文件被拆成多个chunk块。
三、小结
对于小文件的,可以直接转二进制存储,对于大于等于16MB的,使用GridFS存储。
希望这篇文章能帮到大家,有错漏之处,欢迎指正。
请多点赞、评论~
完。