实例带你了解GaussDB的索引管理
本文分享自华为云社区《GaussDB数据库的索引管理》,作者: Gauss松鼠会小助手2。
一、引言
GaussDB数据库是华为公司倾力打造的自研企业级分布式关系型数据库,索引的设计和管理对于提高查询性能至关重要。下面将通过实际例子深入研究GaussDB数据库的索引管理。

二、GaussDB数据库中的索引基本概念
2.1 什么是GaussDB索引?
GaussDB索引是一种数据结构,用于加速对表中数据的检索和查询。比如,在一个巨大的客户订单表中,可以通过对订单号列创建索引,加速根据订单号查询订单信息的速度。
2.2 GaussDB索引的作用
GaussDB索引的主要作用是优化查询性能,减少数据检索的开销。通过使用不同类型的索引,GaussDB能够在各种查询场景下提供高效的数据定位和访问。
三、GaussDB支持的索引类型
3.1 B-Tree索引
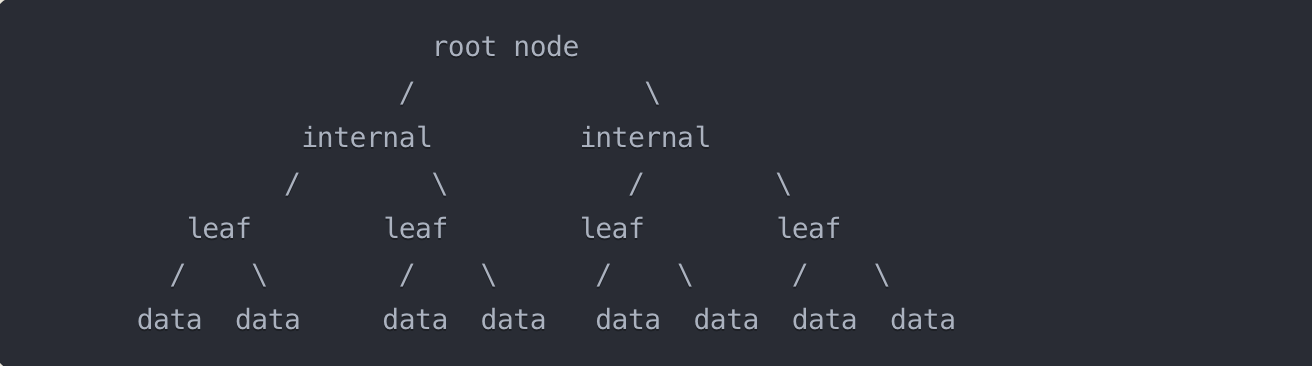
B-Tree索引是一种平衡树,由根节点、内部节点和叶子节点组成。根节点和内部节点存储键值和指向子节点的指针,叶子节点存储实际的数据。
适用场景: 适用于单一值的列,例如整数、字符串等。
结构: B-Tree(平衡树)是一种有序树,每个节点包含多个键,并且子节点的键值范围是确定的。
优势: 高效支持范围查询、等值查询和排序操作。
示例: 在用户表中,通过用户ID列创建B-Tree索引,可以加速按用户ID查询的速度。
3.2 GIN索引

GIN索引是一种倒排索引,适用于存储和查找由多个键值组成的复合值的数据。它由一个元数据根节点、一个初始条目列表(entry list)和多个从属数据区(pending data pages)组成
适用场景: 适用于包含多个数值或文本值的列,例如标签、数组等。
结构: Generalized Inverted Index(广义反向索引),可用于加速包含多个项的列的查询。
优势: 高效支持包含和排除多个值的查询。
示例: 在文章表中,通过对标签列创建GIN索引,可以加速检索包含特定标签的文章。
3.3 GiST索引
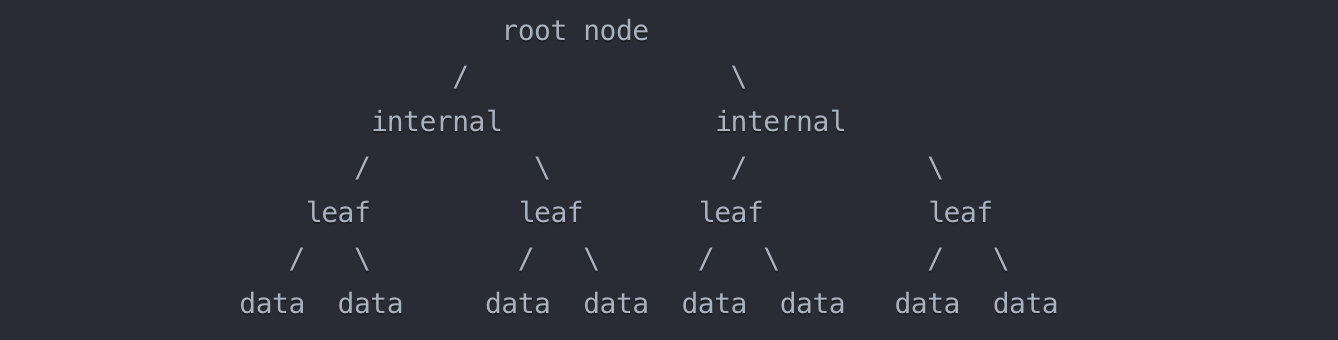
GiST索引是一种平衡树索引,类似于B-Tree索引,但它支持各种各样的数据类型和查询方式。GiST索引由根节点、内部节点和叶子节点组成。每个节点包含一个或多个条目,每个条目由一个键和一些属性组成。
适用场景: 适用于各种数据类型,尤其是用于高维数据和非标量数据类型的查询。
结构: Generalized Search Tree(广义搜索树),适用于支持多种查询操作。
优势: 高效支持范围查询、相似度查询和一些特殊数据类型的查询。
示例: 在地理信息系统中,通过GiST索引加速空间数据的查询,例如查询地理位置范围内的数据。
3.4 SP-GiST索引

SP-GiST索引是GiST索引的一个变体,增加了"空间分区"的特性。SP-GiST索引同样由根节点、内部节点和叶子节点组成。每个内部节点都包含子节点范围的元组描述,叶节点存储实际数据。SP-GiST适用于二维空间数据等。
适用场景: 专门用于处理空间数据,提供对复杂空间数据的高效查询支持。
结构: Space-Partitioned Generalized Search Tree(空间划分广义搜索树)。
优势: 高效支持空间数据的范围查询、相交查询等。
示例: 在包含城市坐标的表中,通过创建SP-GiST索引可以加速根据地理位置范围查询城市的速度。
四、创建和管理GaussDB索引
4.1 创建索引
在GaussDB中,可以使用以下SQL语句创建索引:
-- 创建B-Tree索引
CREATE INDEX btree_index ON user_table USING btree(user_id);
-- 创建GIN索引
CREATE INDEX gin_index ON article_table USING GIN(tags);
-- 创建GiST索引
CREATE INDEX gist_index ON spatial_data_table USING GiST(geometry_column);
-- 创建SP-GiST索引
CREATE INDEX sp_gist_index ON city_table USING SP-GiST(geo_location);
4.2 删除索引
通过以下SQL语句可以在GaussDB中删除索引:
-- 删除索引
DROP INDEX btree_index;
4.3 索引的优化和性能考虑
在创建索引时,需要考虑查询的模式、数据分布和表的大小。例如,对于一个日志表,可能只在时间戳列上创建定期维护的B-Tree索引,以加速按时间范围查询的性能。
示例:
场景描述
假设有一个订单管理系统,其中有一个庞大的订单表(order_table),记录了每个订单的详细信息,包括订单号、客户ID、商品ID、订单金额等。在这个场景下,我们希望优化订单表的查询性能,特别是按照客户ID查询该客户的所有订单记录。
创建初始索引
首先,我们为订单表的客户ID列创建一个初始的B-Tree索引:
-- 创建初始B-Tree索引
CREATE INDEX idx_customer_id ON order_table USING btree(customer_id);
查询性能分析
通过常规查询分析,我们发现在按照客户ID查询订单时,查询性能不如预期。这可能是因为订单表的数据分布较广,B-Tree索引在这种情况下的性能有限。
优化索引
为了优化索引性能,我们决定尝试使用GIN索引,以适应多值的情况。我们将客户ID列的值转化为数组,然后使用GIN索引:
-- 创建GIN索引
CREATE INDEX idx_customer_id_gin ON order_table USING GIN(ARRAY[customer_id]);
再次查询性能分析
通过再次进行客户ID查询,我们发现使用GIN索引后的性能有了明显提升。GIN索引更适用于包含多个客户ID的情况,通过将值存储在数组中,可以更有效地支持这种查询模式。
优化结果
通过优化索引,我们成功提高了按照客户ID查询订单的性能。然而,需要注意的是,索引的优化是一个动态过程,需要根据实际查询模式和数据分布进行调整。定期监测和评估索引的性能是数据库维护的一部分,以确保系统保持高性能状态。
五、GaussDB索引的使用注意事项
5.1 维护成本
在GaussDB中,索引的维护成本是需要考虑的因素之一。频繁的插入、更新和删除操作可能导致索引的重新构建,影响系统性能。
5.2 索引选择和优化
过多或不必要的索引可能导致性能下降,因此在设计数据库时,需要仔细选择哪些列需要索引,并根据查询需求进行优化。
六、GaussDB索引实践
在实际应用中,理解业务需求、数据分布和查询模式是制定索引最佳实践的关键。通过合理配置索引,可以在GaussDB数据库中实现高效、稳定的查询性能。
总体而言,深入理解GaussDB数据库索引的原理和使用方法,结合实际业务需求进行灵活配置,将有助于建立高性能、可维护的数据库系统。
热门相关:年轻的女仆 岳母的简介 飞虎精英之人间有情国语 野蛮之徒 不伦之夜