读图数据库实战笔记01_初识图
1. 图论
1.1. 起源于莱昂哈德·欧拉在1736年发表的一篇关于“哥尼斯堡七桥问题”的论文
1.2. 要解决这个问题,该图需要零个或两个具有奇数连接的节点
1.3. 任何满足这一条件的图都被称为欧拉图
1.4. 如果路径只访问每条边一次,则该图具有欧拉路径
1.5. 如果路径起点和终点相同,则该图具有欧拉回路,或称为欧拉环
2. 图
2.1. 顶点和边的集合
2.2. 示例
2.2.1. 路线图
2.2.2. 组织结构图
2.3. 当要思考的数据集含有大量高度相互关联的项时,也可以将该数据集描述为一个由相关事物组成的网络,这也是图的另一种说法
3. 顶点
3.1. 图中零条、一条或多条边经过的点
3.2. 节点或实体
4. 边
4.1. 图中两个顶点之间的关系
4.2. 关系、链接或连接
5. 图数据库
5.1. 一种数据存储引擎
5.1.1. 将包含顶点和边的基本图结构与持久化技术和遍历(查询)语言相结合
5.1.2. 以创建针对高度关联数据的存储和快速检索进行优化的数据库
5.2. 实体之间的关系与数据中的实体同等重要,甚至比后者更加重要
5.2.1. 用开发人员的话来说,边和顶点一样,都是“一等公民”
5.3. 可以用于更准确、更容易地表示和推理现实世界中的关系
5.4. 将数据存储为顶点(节点、组件)和边(关系)
5.5. Neo4j、Apache TinkerPop的Gremlin Server、JanusGraph和TigerGraph
5.6. 默认情况下,只有关系数据库和图数据库才具有将数据中的实体关联起来的功能
5.7. 优势
5.7.1. 递归查询
5.7.1.1. 组织中员工的汇报层次结构或者组织结构图
5.7.1.2. 会连续执行多次,反复调用自己,直到满足某种终止条件
5.7.1.3. 关系数据库不能很好地处理递归操作
5.7.1.4. 图数据库能够利用其表示丰富关系的能力,干净、高效地处理无边界递归查询
5.7.1.5. 嵌套查询和递归查询(如前面的层次结构示例所示)是图数据库擅长解答的疑问类型
5.7.2. 复合结果类型
5.7.2.1. 订单和产品报告示例
5.7.2.2. 能够返回包含不同数据类型的结果集
5.7.2.3. 关系数据库指定联合返回的结果集必须包含一致的列
5.7.2.3.1. 在稀疏数据的情况下,这不仅增加了返回的数据量,还降低了数据结构的描述性
5.7.3. 路径
5.7.3.1. 过河问题
5.7.3.2. 一组顶点和边的序列,描述遍历如何在图中移动
5.8. 请把注意力集中在图数据库如何优雅地处理关系数据库里的UNION操作上
5.9. 可以把图数据库设计得能够容忍不断发展变化的数据
5.10. 使用
5.10.1. 并不一定全部使用图数据库,也并不一定全部不使用图数据库
5.10.2. 不要害怕尝试用图数据库来解决问题的一部分
5.10.3. 使用图数据库的多模型方法(即混合使用关系数据库和图数据库)很常见
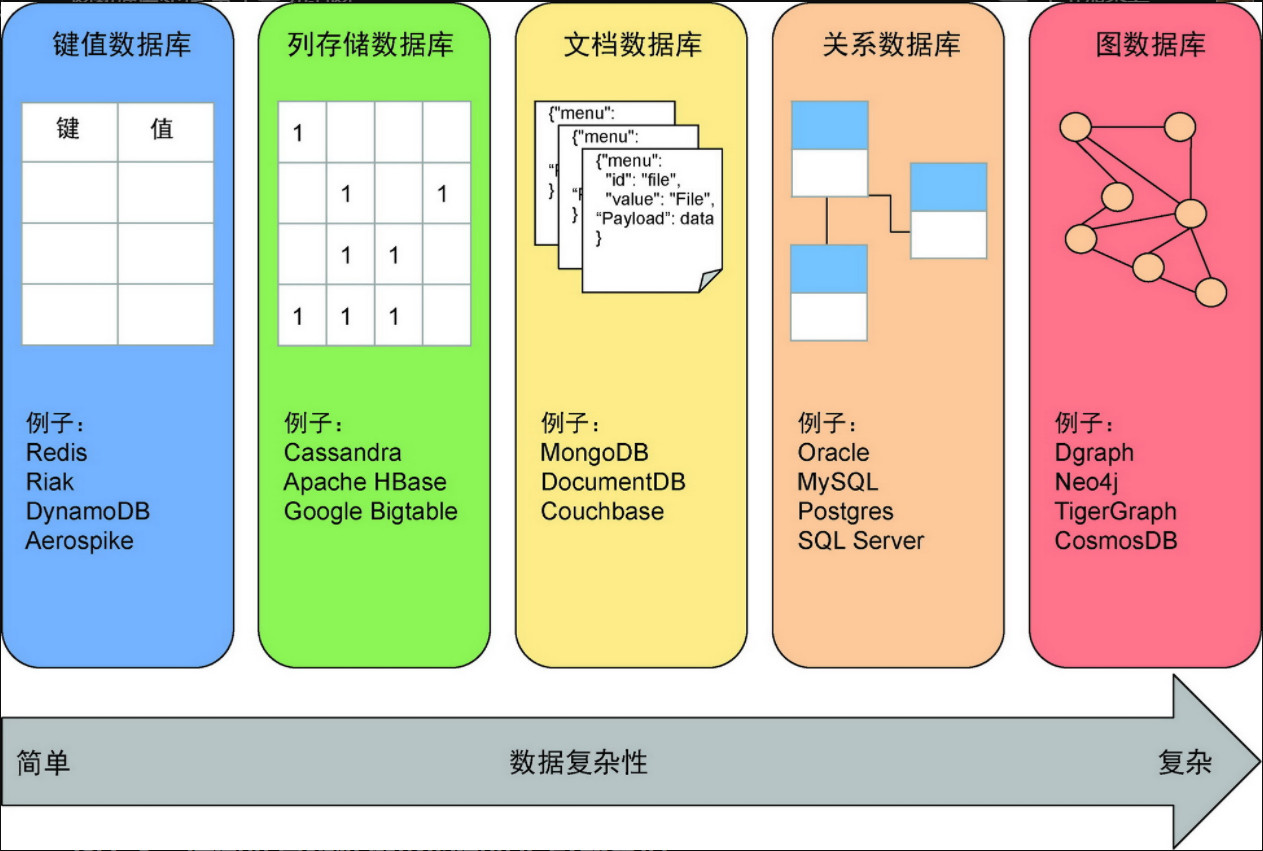
6. 比较
6.1. 键值数据库
6.1.1. 所有数据都由唯一标识符(键)和关联的数据对象(值)表示
6.1.2. Berkeley DB、RocksDB、Redis和Memcached
6.2. 列存储数据库
6.2.1. 面向列、宽列式数据库
6.2.2. 数据按列来存储
6.2.2.1. 可能每行有大量的列
6.2.2.2. 可能每行的列数不一样
6.2.3. Apache HBase、Azure Table Storage、Apache Cassandra和Google Cloud Bigtable
6.3. 文档数据库
6.3.1. 面向文档数据库
6.3.2. 将数据存储到带有唯一键的文档中
6.3.3. 该文档可以具有不同的模式,也可以包含嵌套数据
6.3.4. MongoDB和Apache CouchDB
6.4. 关系数据库
6.4.1. 将数据存储在包含具有严格模式行结构的表中,允许在表之间连接行来建立关系
6.4.2. 关系数据库中的查找表或链接表使用的不是查询时的指针结构,而是存储了有关关系属性的结构,类似于图数据库中的边结构
6.4.3. PostgreSQL、Oracle Database和Microsoft SQL Server
6.5. 数据复杂性
7. Apache TinkerPop
7.1. TinkerPop是Apache软件基金会的顶级项目
7.2. 提供了一个与厂商无关的开源图计算框架
7.3. 具有事务(OLTP)能力和分析(OLAP)能力
7.4. 有广泛的第三方库可供使用
8. TinkerGraph
8.1. 一个内存图引擎
8.2. 支持OLTP负载和OLAP负载
8.3. TinkerPop Gremlin Server和Gremlin Console的一部分
8.4. TinkerPop的全功能开源实现
8.4.1. 被作为TinkerPop API的参考实现构建出来的
8.5. 并非一个你能下载的软件
8.5.1. 可下载软件(如Gremlin Server 和Gremlin Console)里的核心引擎
9. Gremlin
9.1. Gremlin遍历语言是TinkerPop项目的图查询语言
9.2. 支持命令式语法和声明式语法
9.2.1. 首选方式是命令式语法
9.3. Gremlin Console
9.3.1. 用于TinkerPop支持图数据库的交互终端应用程序
9.3.2. 允许用户连接到本地或远程的数据库,将数据加载到图中,并交互式地在图上进行遍历
9.3.3. 能作为自带内存图数据的独立应用程序使用
9.3.4. 能作为图数据库服务器的客户端使用
9.4. Gremlin Server
9.4.1. 允许非JVM客户端与基于JVM的图数据库进行通信
9.4.2. 提供能让部署在不同服务器上的数据库相互通信的机制
9.5. Gremlin语言变体
9.5.1. 允许开发人员既使用Gremlin作为查询语言,又能通过他们选择的开发语言方言来实现
9.5.2. 主张以应用程序编程语言的风格来编写Gremlin遍历
9.5.2.1. Java开发人员使用Java语法
9.5.2.2. .NET开发人员使用.NET语法
10. 用例/场景
10.1. 从社交网络分析、推荐引擎、依赖性分析、欺诈检测和主数据管理,到搜索问题和互联网上的研究,你很快就能列出一个适合使用图数据库的用例列表
10.2. 判断一个用例是好还是坏的最重要因素是对要解答的疑问有深入的了解
10.3. 选择/搜索
10.3.1. 侧重于寻找一组具有共同属性(如姓名、位置或雇主)的实体
10.3.2. 不需要数据中丰富的关系
10.3.3. 建议使用诸如PostgreSQL之类的本地数据库或诸如Apache Solr和Elasticsearch之类的搜索技术
10.3.4. 使用RDBMS或搜索技术
10.4. 获取数据相关性或递归数据
10.4.1. 图数据库比任何其他类型数据引擎都能更好地利用这些信息
10.4.2. 图数据库查询语言更适用于推断数据内部的关系
10.4.3. 使用图数据库
10.5. 聚合
10.5.1. 数据聚合查询是关系数据库的一个优秀用例
10.5.2. 关系数据库经过优化,能以最小的开销快速执行复杂的聚合查询
10.5.3. 可以在图数据库中执行,但是图遍历的本质要求接触更多的数据。这会导致更高的查询延迟和更多的资源消耗
10.5.4. 使用RDBMS
10.6. 模式匹配
10.6.1. 基于实体关联方式的模式匹配是充分利用图数据库功能的一个主要例子
10.6.2. 推荐引擎、欺诈检测和入侵检测
10.6.3. 使用图数据库
10.7. 中心性、聚集性和影响力
10.7.1. 一个实体相对于另一个实体的影响力或重要性是图数据库的典型用例
10.7.2. 识别基础设施的关键部分,或者定位数据中的实体组
10.7.3. 要考虑实体、实体之间的关系、事件关系和邻近关系
10.7.4. 使用图数据库
10.8. 数据结构的灵活性不能作为选择图数据库的充分理由,但与其他功能相结合,很可能足以使你转而使用图数据库
10.9. 即使业务领域模型天生适合使用图数据库,但是如果你的具体技术问题并不依赖于图中的关系来求解,那么也应该考虑其他选择
11. SQL
11.1. SQL查询中包含大量join可能表明图数据库是一个很好的选择,但并不能确定
11.2. SQL查询中的大量join通常是数据模型规范化的良好标志
11.3. 当这些join并非用于检索引用数据(如关系数据库中的第三个范式所做的那样),而是用于将记录项链接在一起(就像父子关系那样)时,就可能需要考虑使用图数据库了
11.4. 当我们不知道要执行的join数量时,使用图数据库的递归查询模式更好
11.5. 命令查询责任分离(CQRS)模式
热门相关:呆萌小昏君:邪尊,花样宠! 茅山神婿 都市御魔人 帝国远征 茅山神婿